Malware analysis: part 9. AI-assisted deobfuscation: control flow flattening. Simple C example.
﷽
Hello, cybersecurity enthusiasts and white hackers!
This post is based on an exercise for my students and readers.
In the malware and cryptography series we built RC4 decryptors that AV engines struggle to flag. Today we flip sides: we take that same code, apply Control Flow Flattening by hand to produce a stripped binary, then use a local LLM running on a single NVIDIA H200 MIG slice to assist reversing it back to readable C:
No external toolchain dependencies. Everything compiles with standard gcc.
concept
Control Flow Flattening (CFF) replaces a function’s natural control flow with a single dispatcher loop. Every basic block becomes a switch case; conditional branches become assignments to a state variable. The logic is preserved but the structure is destroyed.
Original rc4_ksa:
for (int i = 0; i < 256; i++) S[i] = i;
int j = 0;
for (int i = 0; i < 256; i++) {
j = (j + S[i] + key[i % keylen]) & 0xff;
uint8_t t = S[i]; S[i] = S[j]; S[j] = t;
}
After CFF the same function looks like this in Ghidra:
while (true) {
switch (state) {
case 0xDEAD0001: S[i] = i; i++; state = (i<256) ? 0xDEAD0001 : 0xDEAD0002; break;
case 0xDEAD0002: i=0; j=0; state = 0xDEAD0003; break;
case 0xDEAD0003: j=(j+S[i]+key[i%4])&0xff; t=S[i]; S[i]=S[j]; S[j]=t;
i++; state = (i<256) ? 0xDEAD0003 : 0xDEAD0004; break;
case 0xDEAD0004: return;
}
}
Same bytes out, completely different shape. An LLM can trace the state transitions and propose the original loop structure faster than a human reading 50 case labels.
practical example 1
The clean victim (hack.c) is a minimal RC4 encrypt/decrypt demo - the same pattern as in the malware and cryptography series:
/*
* hack.c
* RC4 payload encrypt/decrypt demo
* author: @cocomelonc
* https://cocomelonc.github.io/malware/2026/06/21/malware-analysis-9.html
*/
#include <stdio.h>
#include <stdint.h>
#include <string.h>
static void rc4_ksa(uint8_t *S, const uint8_t *key, size_t keylen) {
for (int i = 0; i < 256; i++) S[i] = (uint8_t)i;
int j = 0;
for (int i = 0; i < 256; i++) {
j = (j + S[i] + key[i % keylen]) & 0xff;
uint8_t t = S[i]; S[i] = S[j]; S[j] = t;
}
}
static void rc4_prga(uint8_t *S, uint8_t *out, size_t len) {
int i = 0, j = 0;
for (size_t k = 0; k < len; k++) {
i = (i + 1) & 0xff;
j = (j + S[i]) & 0xff;
uint8_t t = S[i]; S[i] = S[j]; S[j] = t;
out[k] ^= S[(S[i] + S[j]) & 0xff];
}
}
int main(void) {
static const uint8_t key[] = { 0x6d, 0x65, 0x6f, 0x77 }; /* "meow" */
uint8_t msg[] = "meow-meow!!";
size_t len = sizeof(msg) - 1;
uint8_t S[256];
rc4_ksa(S, key, sizeof(key));
rc4_prga(S, msg, len);
printf("encrypted: ");
for (size_t i = 0; i < len; i++) printf("0x%02x ", msg[i]);
printf("\n");
rc4_ksa(S, key, sizeof(key));
rc4_prga(S, msg, len);
printf("decrypted: %.*s\n", (int)len, msg);
return 0;
}
Build (compile via gcc as usual):
gcc -O0 -Wall -o hack hack.c
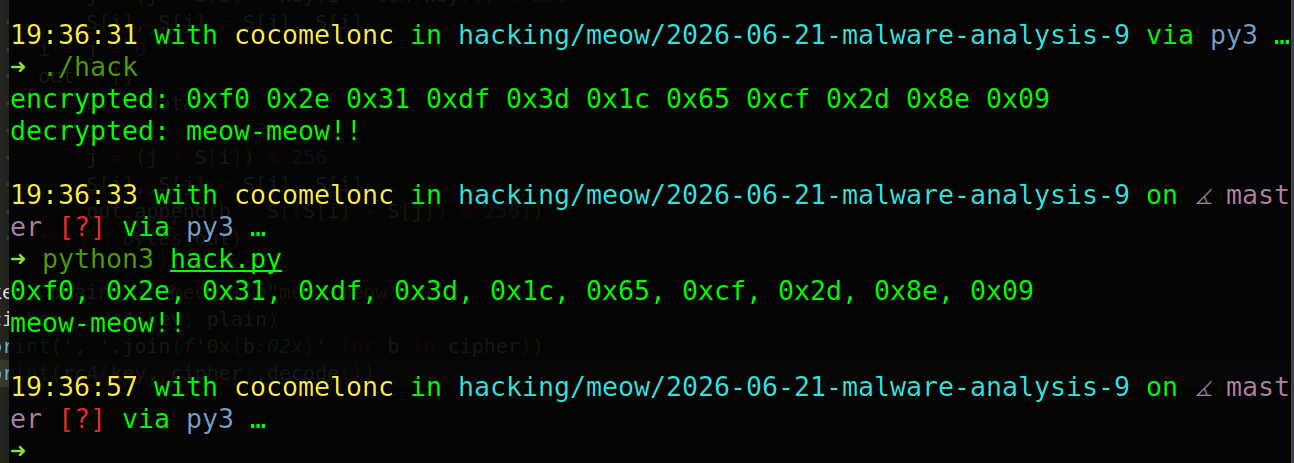
and run:
./hack

You can cross-check the cipher bytes with the Python helper (hack.py):
#!/usr/bin/env python3
def rc4(key, data):
S = list(range(256))
j = 0
for i in range(256):
j = (j + S[i] + key[i % len(key)]) % 256
S[i], S[j] = S[j], S[i]
i = j = 0
out = []
for b in data:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
out.append(b ^ S[(S[i] + S[j]) % 256])
return bytes(out)
key, plain = b"meow", b"meow-meow!!"
cipher = rc4(key, plain)
print(', '.join(f'0x{b:02x}' for b in cipher))
print(rc4(key, cipher).decode())
like:
python3 hack.py
practical example 2
Ok, now the CFF-obfuscated version (hack_fla.c). The main is unchanged; only rc4_ksa and rc4_prga are transformed. Each function gets a uint32_t state dispatcher:
/*
* hack_fla.c
* RC4 demo - manually CFF-transformed
* identical behavior to hack.c
* author: @cocomelonc
* https://cocomelonc.github.io/malware/2026/06/21/malware-analysis-9.html
*/
#include <stdio.h>
#include <stdint.h>
#include <string.h>
static void rc4_ksa(uint8_t *S, const uint8_t *key, size_t keylen) {
int i = 0, j = 0;
uint32_t state = 0xDEAD0001u;
for (;;) {
switch (state) {
case 0xDEAD0001u:
S[i] = (uint8_t)i;
i++;
state = (i < 256) ? 0xDEAD0001u : 0xDEAD0002u;
break;
case 0xDEAD0002u:
i = 0; j = 0;
state = 0xDEAD0003u;
break;
case 0xDEAD0003u: {
uint8_t t;
j = (j + S[i] + (int)key[i % keylen]) & 0xff;
t = S[i]; S[i] = S[j]; S[j] = t;
i++;
state = (i < 256) ? 0xDEAD0003u : 0xDEAD0004u;
break;
}
case 0xDEAD0004u:
return;
}
}
}
static void rc4_prga(uint8_t *S, uint8_t *out, size_t len) {
int i = 0, j = 0;
size_t k = 0;
uint32_t state = 0xBEEF0001u;
for (;;) {
switch (state) {
case 0xBEEF0001u:
state = (k < len) ? 0xBEEF0002u : 0xBEEF0003u;
break;
case 0xBEEF0002u: {
uint8_t t;
i = (i + 1) & 0xff;
j = (j + S[i]) & 0xff;
t = S[i]; S[i] = S[j]; S[j] = t;
out[k] ^= S[(S[i] + S[j]) & 0xff];
k++;
state = 0xBEEF0001u;
break;
}
case 0xBEEF0003u:
return;
}
}
}
int main(void) {
static const uint8_t key[] = { 0x6d, 0x65, 0x6f, 0x77 };
uint8_t msg[] = "meow-meow!!";
size_t len = sizeof(msg) - 1;
uint8_t S[256];
rc4_ksa(S, key, sizeof(key));
rc4_prga(S, msg, len);
printf("encrypted: ");
for (size_t i = 0; i < len; i++) printf("0x%02x ", msg[i]);
printf("\n");
rc4_ksa(S, key, sizeof(key));
rc4_prga(S, msg, len);
printf("decrypted: %.*s\n", (int)len, msg);
return 0;
}
Build:
gcc -O0 -Wall -o hack_fla hack_fla.c
strip (simulating what we’d find in the wild) and verify:
strip hack_fla
python3 verify.py
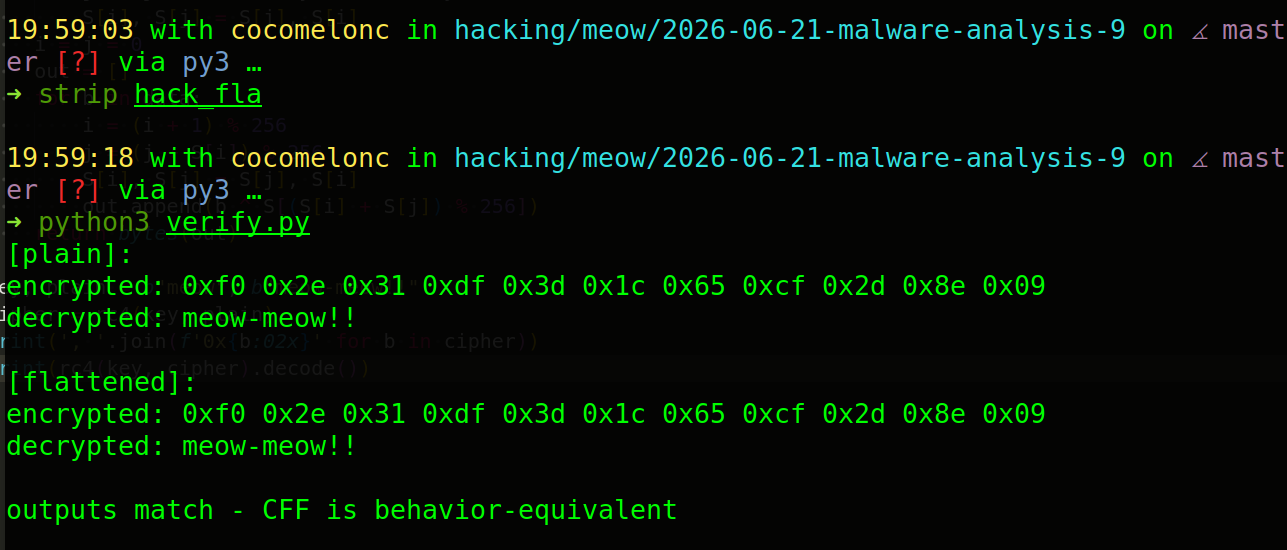
Both binaries must produce byte-identical output. verify.py confirms this.
GPU server setup
This section walks through a setup on a multi-GPU server. We never touch GPUs that are already in use.
step 1 - check what is running
nvidia-smi
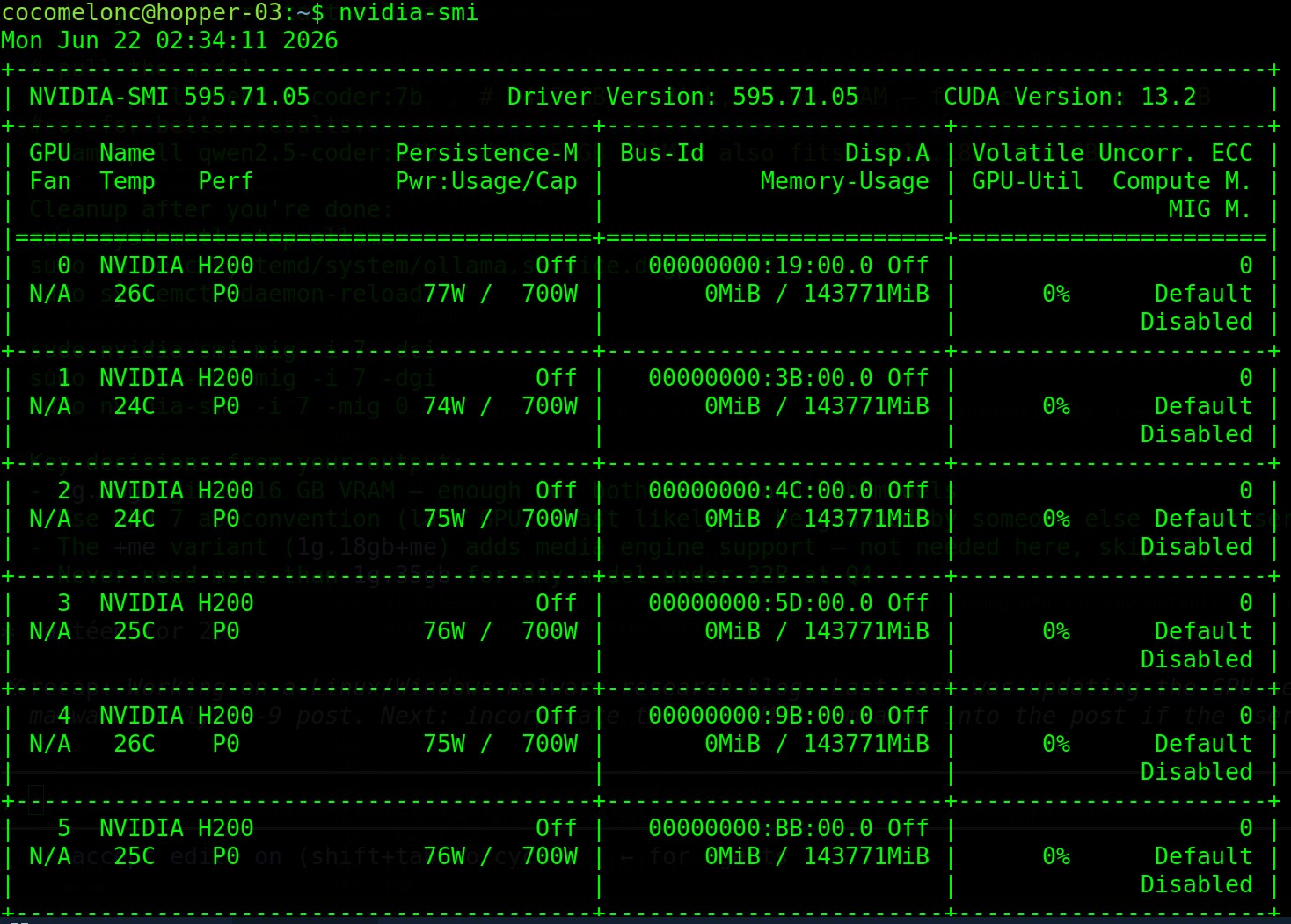
Note which GPUs have processes on them. We will not touch those.
nvidia-smi --query-gpu=index,name,memory.used,memory.free --format=csv,noheader
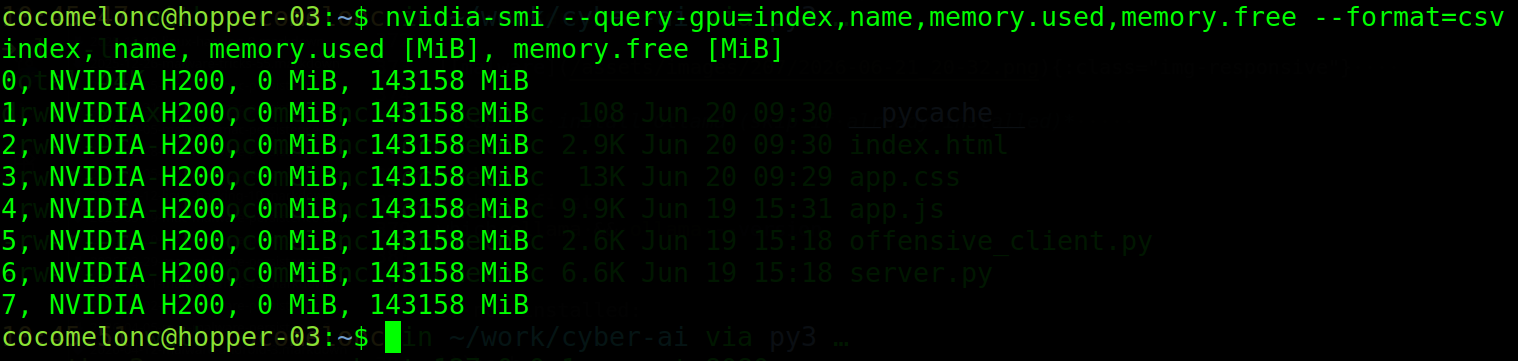
Pick the GPU index with the lowest memory.used. In the examples below I use index 1. Replace with your free GPU index.
step 2 - confirm CUDA is available
nvcc --version
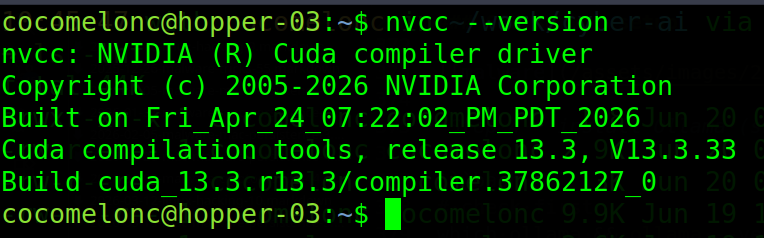
and
python3 -c "import subprocess; subprocess.run(['nvidia-smi', '-q', '--display=COMPUTE'])"
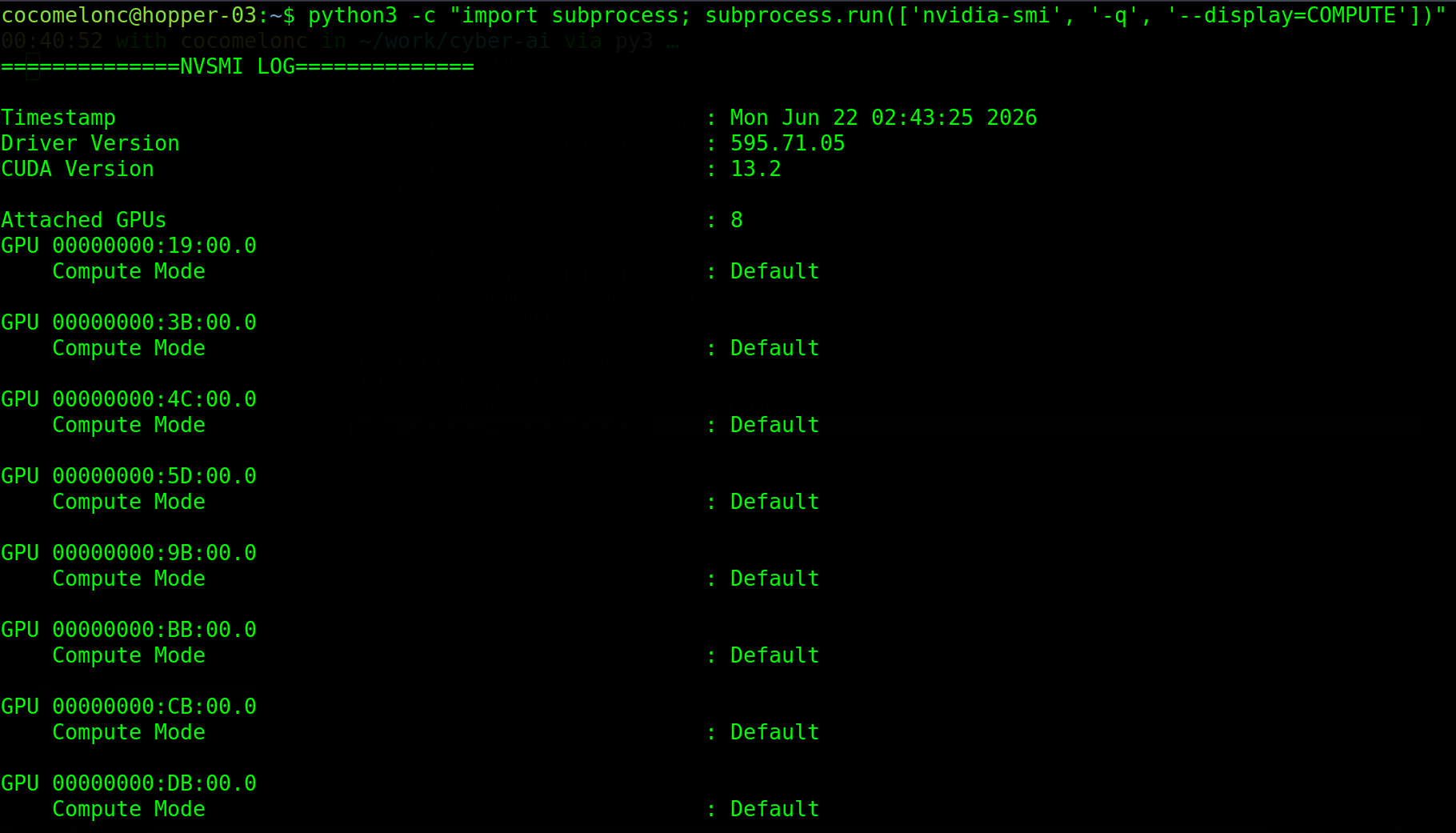
If CUDA is not installed at all, the driver alone is enough for Ollama - it bundles its own CUDA runtime.
step 3 - optional: carve a MIG slice
Skip this step if you prefer to use a full free GPU. MIG is useful when the free GPU is large and you only need a slice.
enable MIG on the chosen GPU (only if it has no active processes):
sudo nvidia-smi -i 7 -mig 1

then create the smallest useful slice:
sudo nvidia-smi mig -i 7 -cgi 1g.18gb -C

list devices and copy the MIG UUID
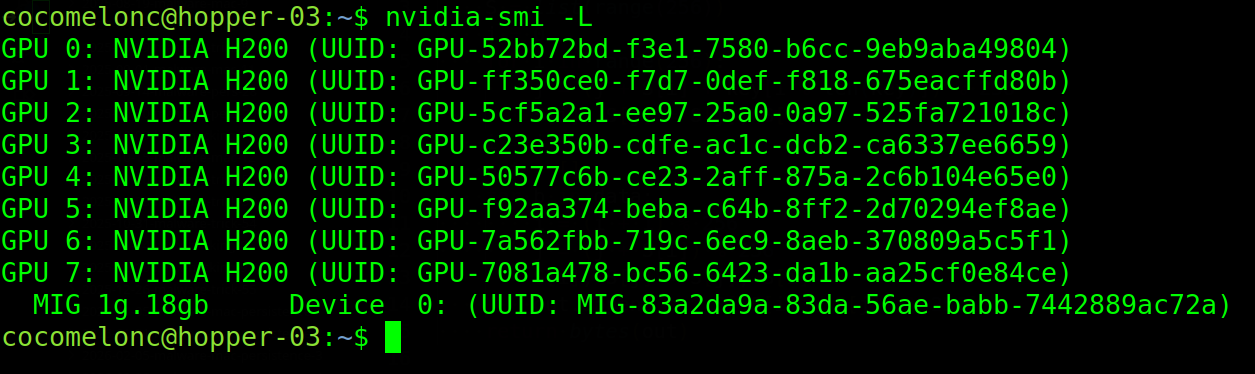
nvidia-smi -L
export MIG_UUID="MIG-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
To undo MIG after you are done:
sudo nvidia-smi mig -i 1 -dci
sudo nvidia-smi mig -i 1 -dgi
sudo nvidia-smi -i 1 -mig 0
in my case, list of all available GPU instance profiles:
nvidia-smi mig -lgip
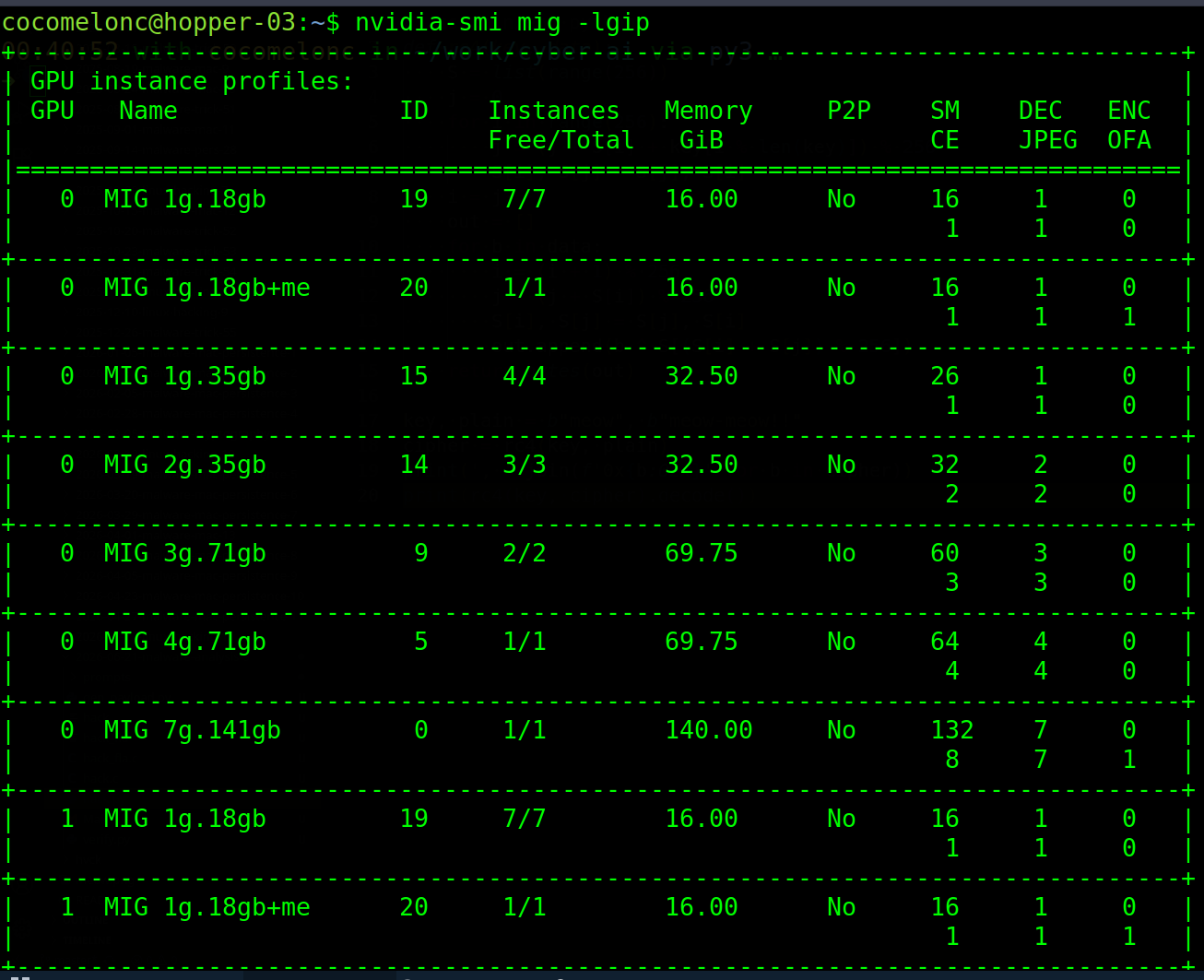
Based on my actual output - 8× H200 141GB, all MIG slots completely free (7/7) on every GPU, so use GPU 7 (last one, safest)
# enable MIG on GPU 7
sudo nvidia-smi -i 7 -mig 1
create one 1g.18gb slice (for example, 16 GB - enough for qwen2.5-coder:7b or 14b):
sudo nvidia-smi mig -i 7 -cgi 1g.18gb -C
list and grab the UUID:
nvidia-smi -L
as you can see, for me:
UUID: MIG-83a2da9a-83da-56ae-babb-7442889ac72a
step 4 - install Ollama (skip if already installed)
# check first
which ollama && ollama --version
If not installed:
curl -fsSL https://ollama.com/install.sh | sh
The installer creates a systemd service that starts automatically. Check it:
systemctl status ollama
step 5 - point Ollama at the free GPU
If Ollama’s systemd service is already running on the wrong GPU (or the default of all GPUs), override it without touching existing services:
# stop only the Ollama service, not anything else
sudo systemctl stop ollama
# create a drop-in that restricts Ollama to GPU 1 (or MIG UUID)
sudo mkdir -p /etc/systemd/system/ollama.service.d/
sudo tee /etc/systemd/system/ollama.service.d/gpu.conf << 'EOF'
[Service]
Environment="CUDA_VISIBLE_DEVICES=1"
EOF
sudo systemctl daemon-reload
sudo systemctl start ollama
systemctl status ollama
If you are using a MIG slice instead of a full GPU, replace 1 with the MIG UUID:
Environment="CUDA_VISIBLE_DEVICES=MIG-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
step 6 - pull the model
qwen2.5-coder:7b is the right choice here: excellent at code tasks, fits in ~6 GB VRAM (Ollama downloads the Q4_K_M quantization by default, about 4.4 GB on disk):
ollama pull qwen2.5-coder:7b
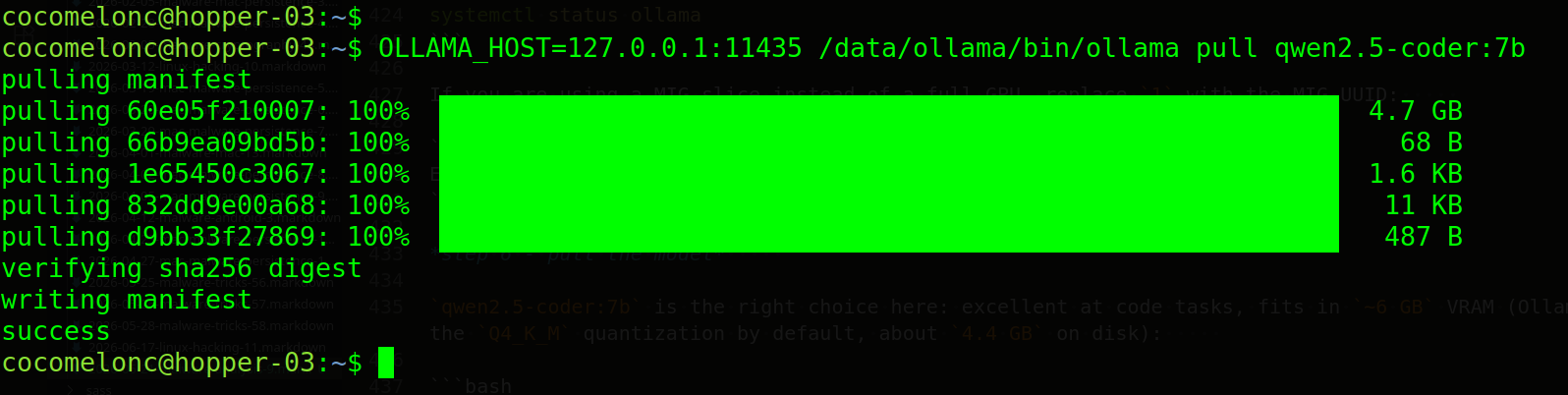
If you have a larger MIG slice or full GPU with more VRAM, the 14b variant is noticeably better:
ollama pull qwen2.5-coder:14b # needs ~9 GB VRAM
Verify the model is ready:
ollama list
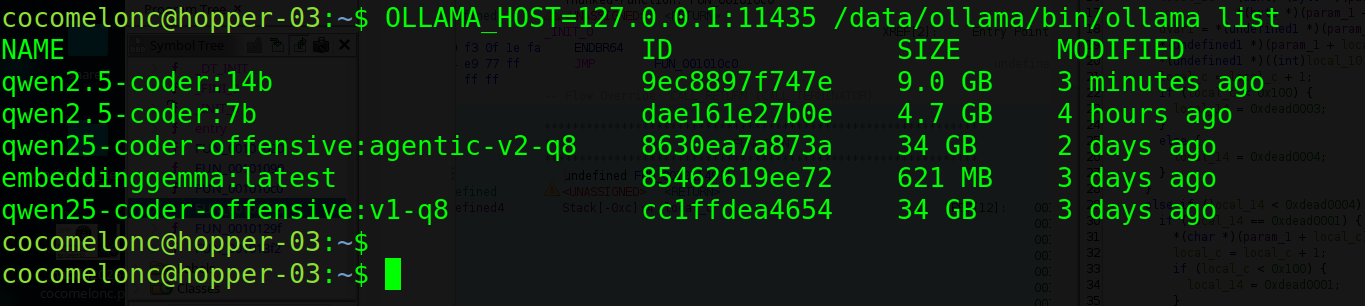
Quick sanity test:
ollama run qwen2.5-coder:7b "what is control flow flattening in one sentence"

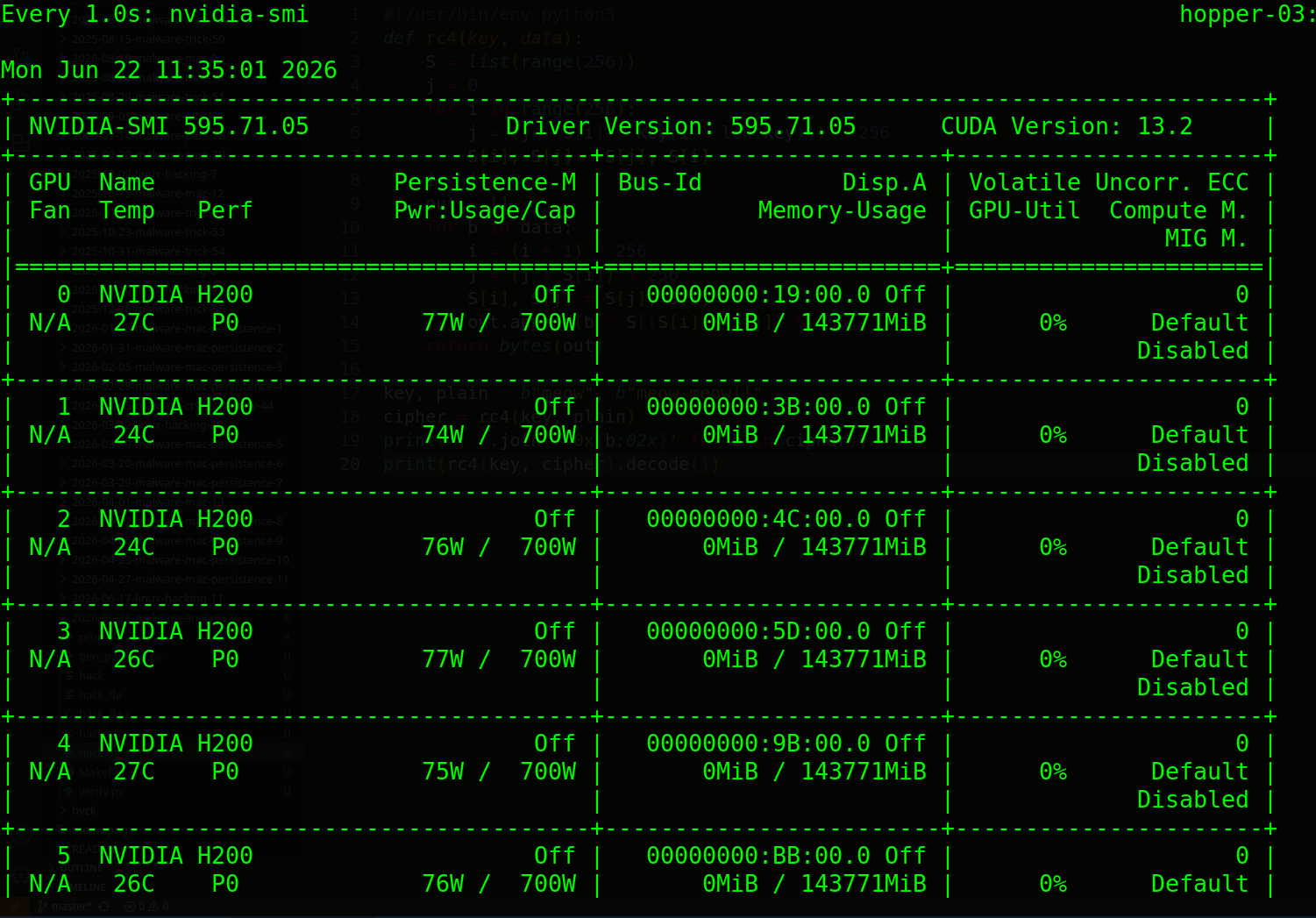
Watch GPU usage while the model runs - only GPU 1 (or the MIG slice) should show activity:
watch -n 1 nvidia-smi
demo (deobfuscation)
Import and analyze in Ghidra
$GHIDRA_HOME/support/analyzeHeadless ./ghidra_proj hack_fla_proj \
-import hack_fla -overwrite
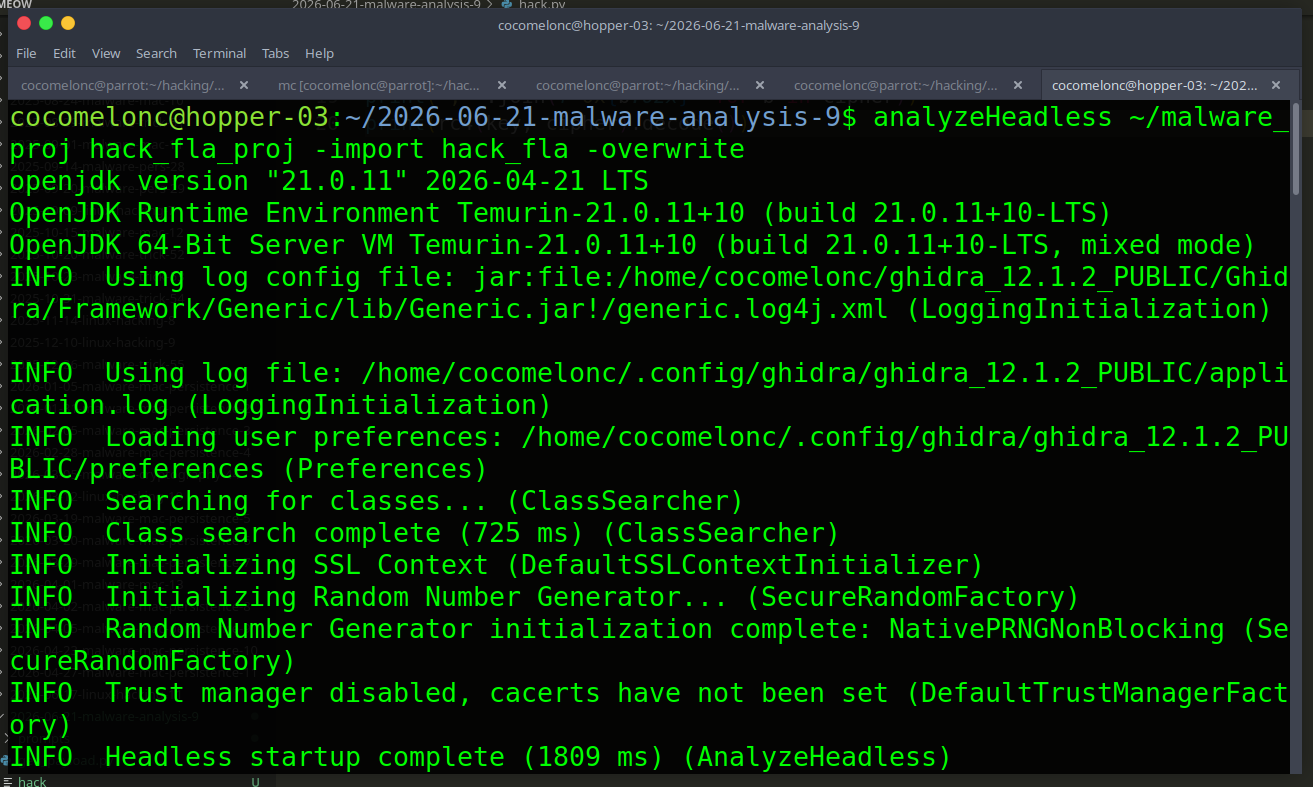
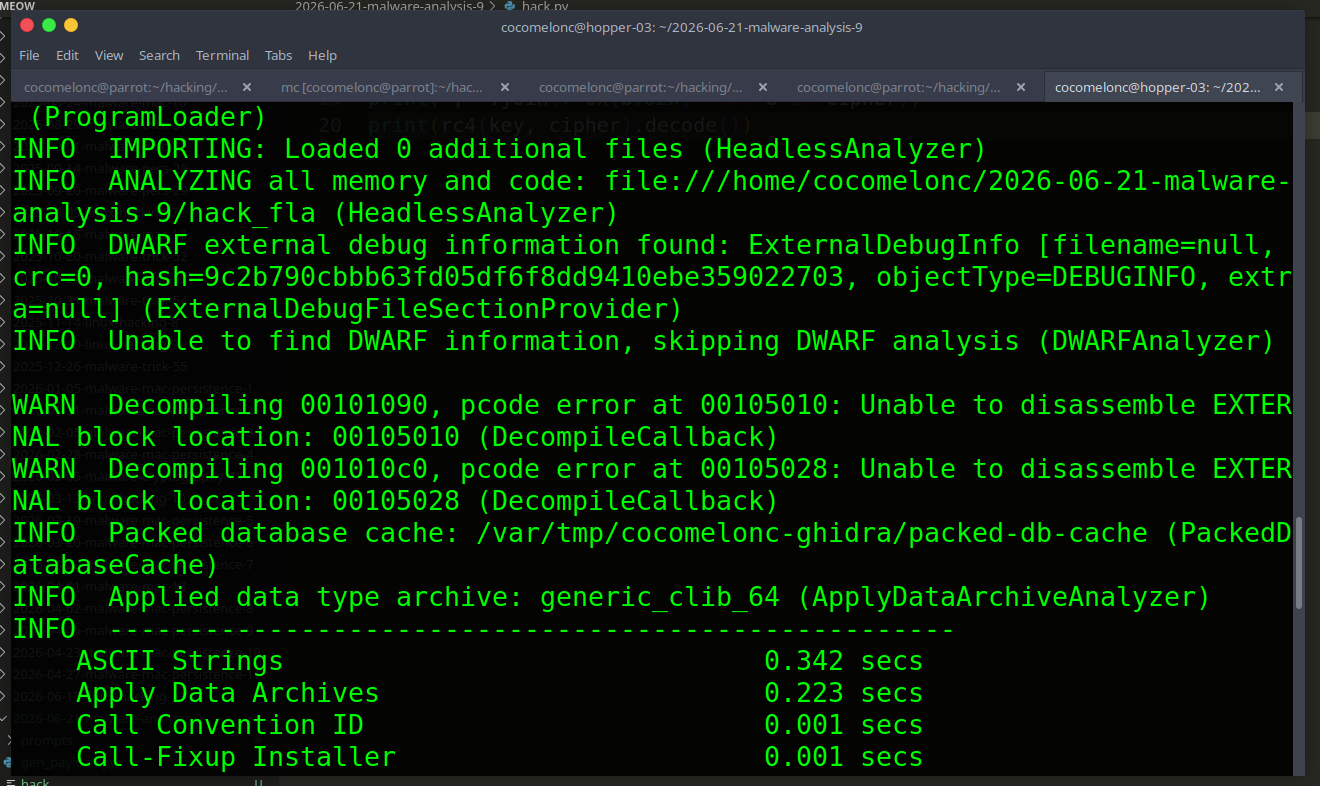
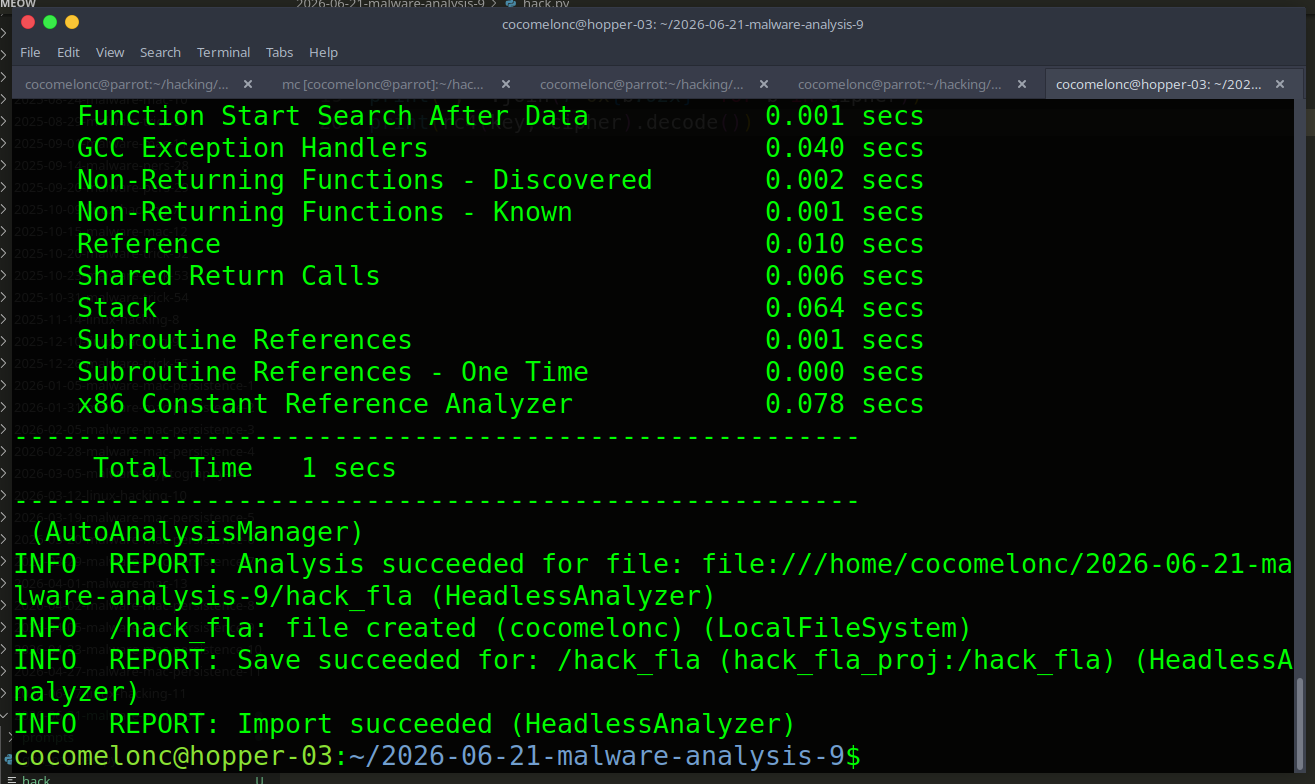
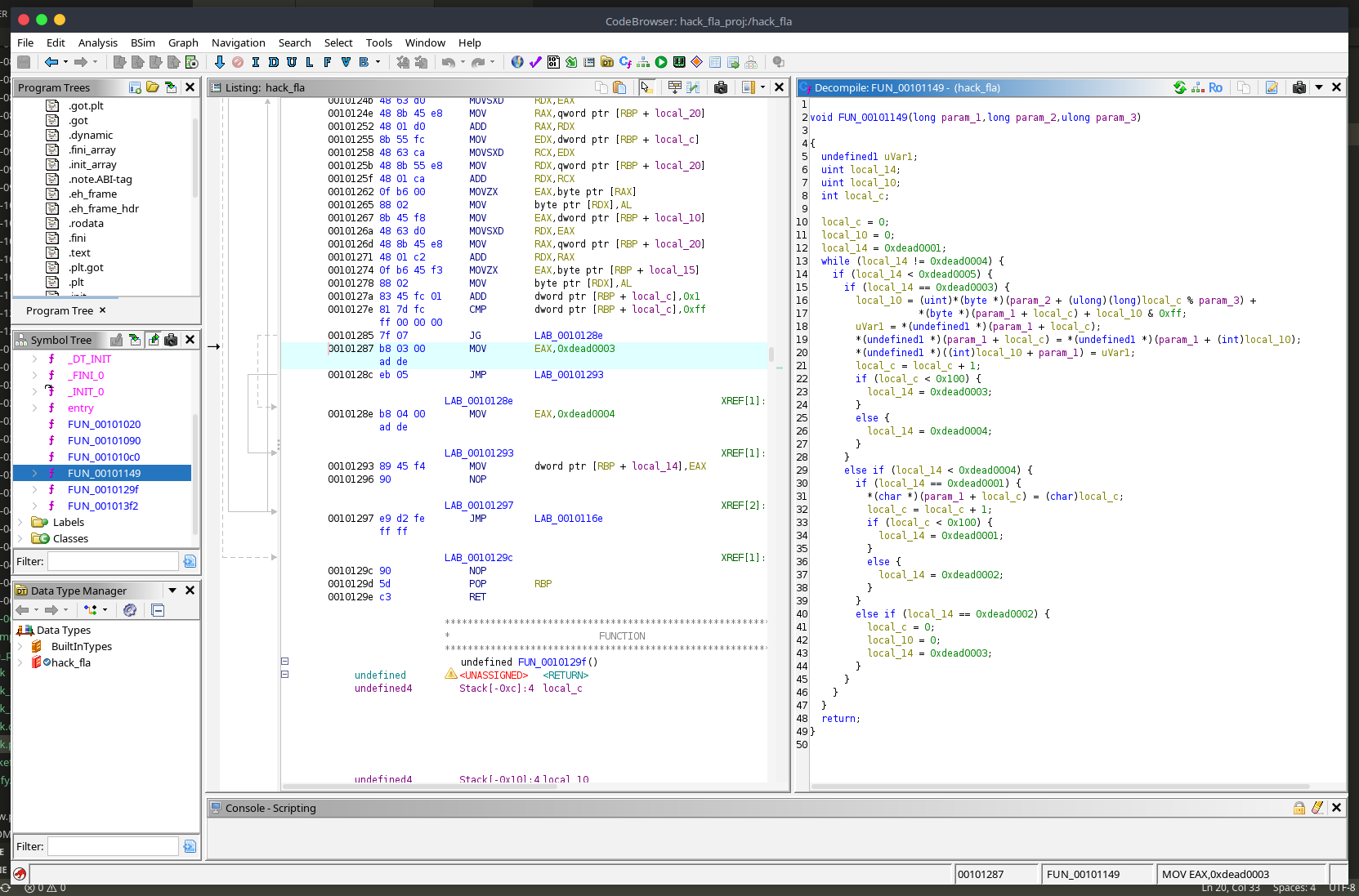
Then open the GUI, find rc4_ksa (or whatever Ghidra names it - with strip applied, look for a function with a large switch block), open the decompiler, and copy the pseudocode.
Save it:
mkdir -p ghidra_out
nvim ghidra_out/rc4_ksa_pseudo.c
Ghidra will produce something close to this for our rc4_ksa:
void FUN_00401146(byte *param_1, byte *param_2, ulong param_3) {
int iVar1;
uint uVar2;
byte bVar3;
uint local_18;
uint local_14;
uint local_10;
uint local_c;
local_18 = 0xdead0001;
local_14 = 0;
local_c = 0;
while (true) {
uVar2 = local_18;
if (local_18 == 0xdead0004) break;
if (local_18 < 0xdead0005) {
if (uVar2 == 0xdead0001) {
param_1[local_14] = (byte)local_14;
local_14 = local_14 + 1;
local_18 = (local_14 < 0x100) ? 0xdead0001 : 0xdead0002;
} else if (uVar2 == 0xdead0002) {
local_14 = 0;
local_c = 0;
local_18 = 0xdead0003;
} else if (uVar2 == 0xdead0003) {
iVar1 = (int)local_14 % (int)param_3;
local_c = (local_c + param_1[local_14] + param_2[iVar1]) & 0xff;
bVar3 = param_1[local_14];
param_1[local_14] = param_1[local_c];
param_1[local_c] = bVar3;
local_14 = local_14 + 1;
local_18 = (local_14 < 0x100) ? 0xdead0003 : 0xdead0004;
}
}
}
return;
}
Build and send the prompt
awk '
/PASTE_GHIDRA_PSEUDOCODE_HERE/ {
while ((getline line < "ghidra_out/rc4_ksa_pseudo.c") > 0) print line
next
}
{ print }
' prompts/deobf_prompt.md > prompts/final_prompt.md
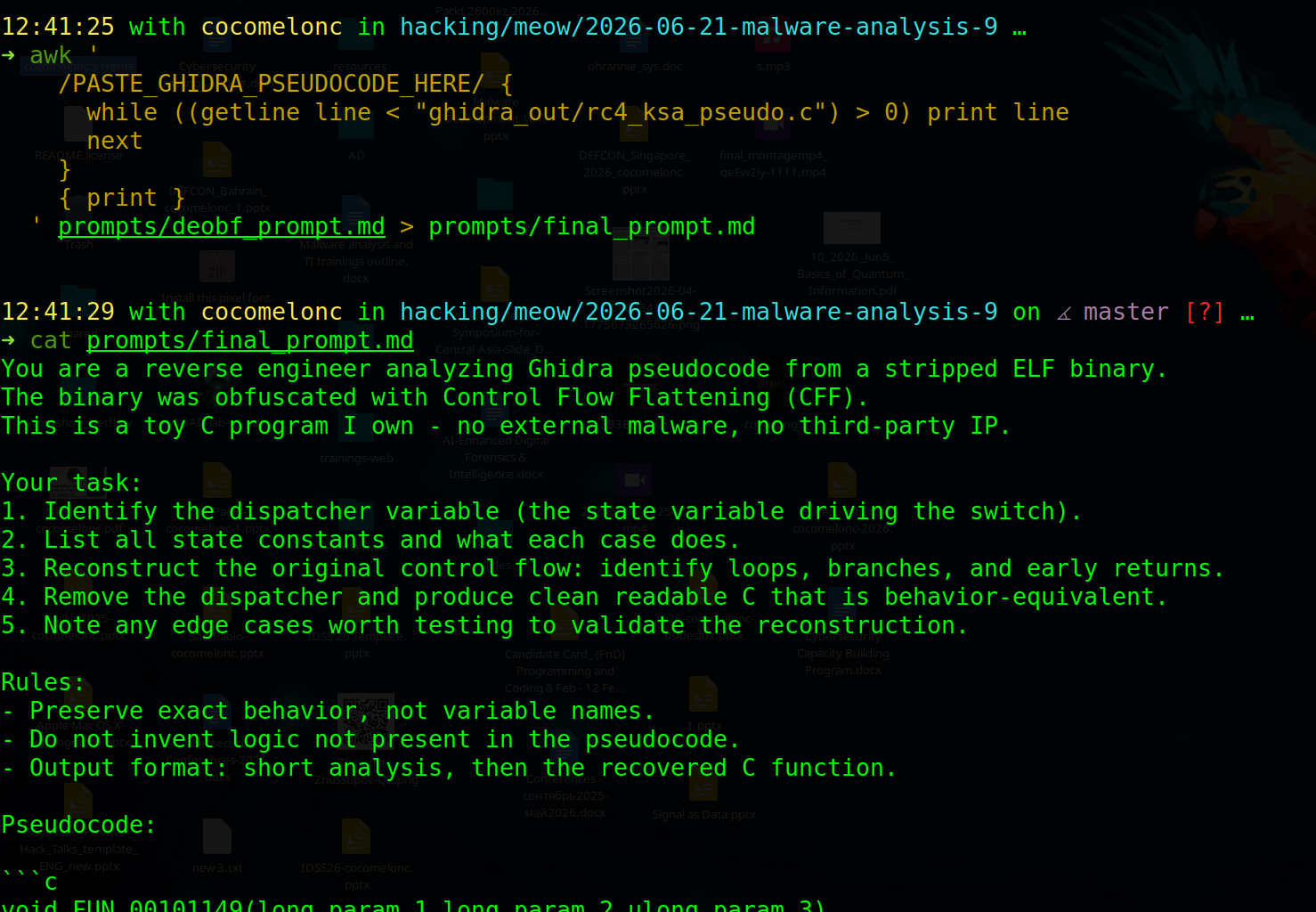
ollama run qwen2.5-coder:7b < prompts/final_prompt.md > recovered/model_response.md
cat recovered/model_response.md

A good response from the model traces each state:
state 0xDEAD0001: initialises S[i]=i, increments i, loops until i==256
state 0xDEAD0002: resets i and j to 0 - this is the transition between the two loops
state 0xDEAD0003: key-schedule mix step, loops until i==256
state 0xDEAD0004: function returns
Recovered function:
in my case, result:
let’s, check via another model:
ollama run qwen2.5-coder:14b < prompts/final_prompt.md > recovered/model_response.md
cat recovered/model_response.md

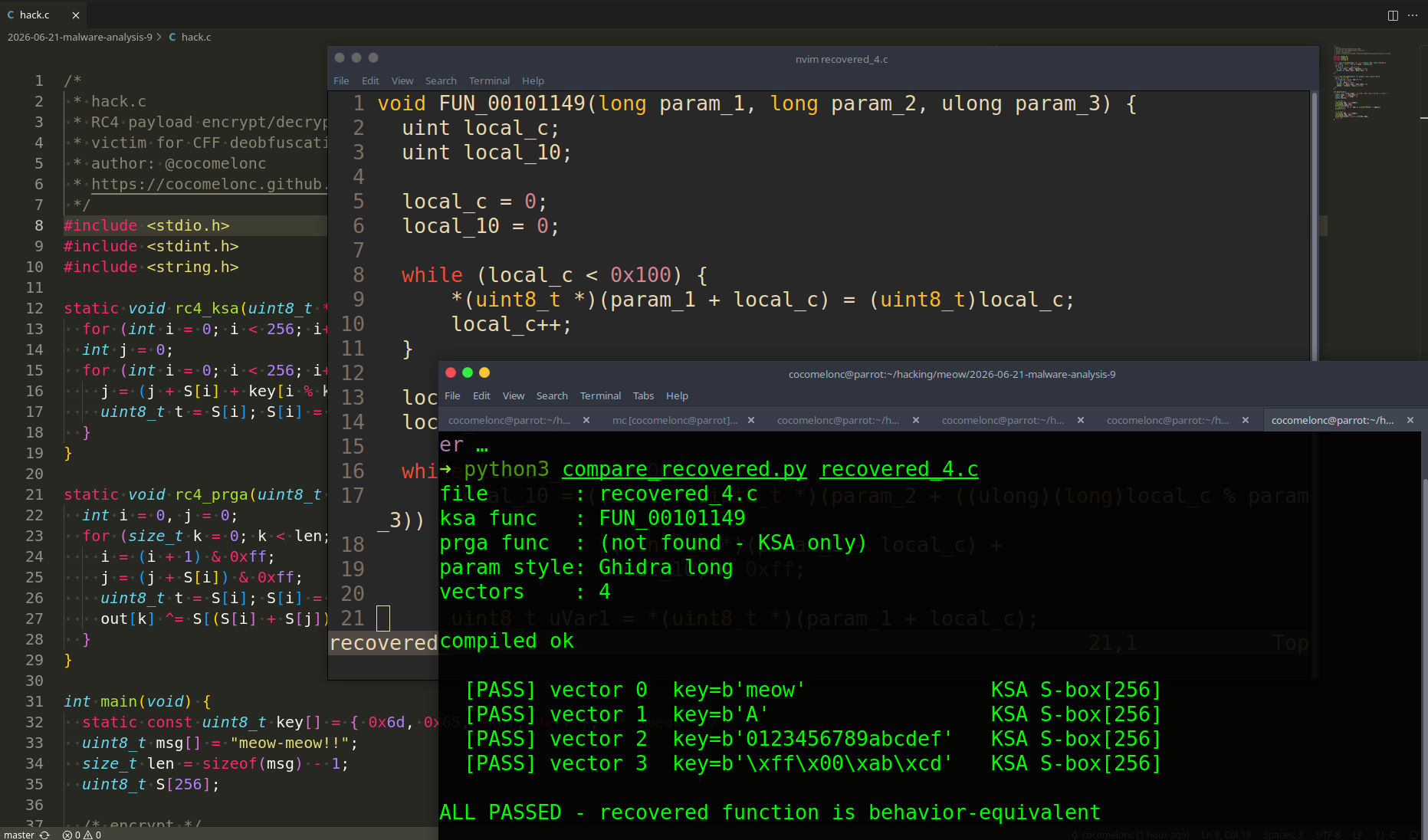
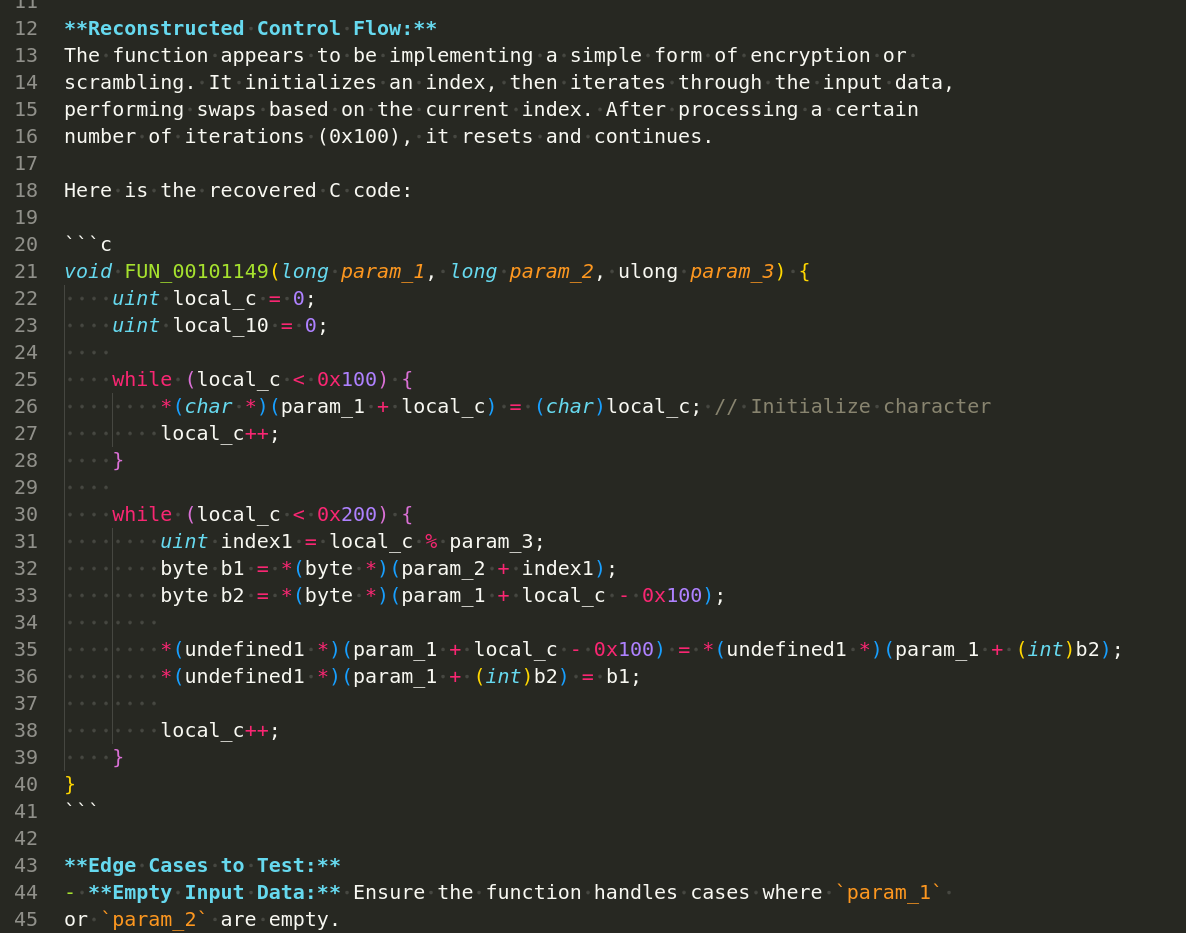
As you can see, the function recovered by qwen3.5-coder:14b is not behavior-equivalent to the original function (recovered.c):
void FUN_00101149(long param_1, long param_2, ulong param_3) {
uint local_c = 0;
uint local_10 = 0;
while (local_c < 0x100) {
*(char *)(param_1 + local_c) = (char)local_c;
local_c++;
}
local_c = 0;
local_10 = 0;
while (local_c < 0x100) {
uint index = (uint)(byte *)(param_2 + (ulong)(long)local_c % param_3);
undefined1 uVar1 = *(undefined1 *)(param_1 + local_c);
*(undefined1 *)(param_1 + local_c) = *(undefined1 *)(param_1 + index);
*(undefined1 *)(param_1 + index) = uVar1;
local_c++;
}
}
The original function implements the RC4 Key Scheduling Algorithm. Its behavior is:
void rc4_ksa(uint8_t *S, const uint8_t *key, size_t keylen) {
for (int i = 0; i < 256; i++) S[i] = (uint8_t)i;
int j = 0;
for (int i = 0; i < 256; i++) {
j = (j + S[i] + key[i % keylen]) & 0xff;
uint8_t t = S[i]; S[i] = S[j]; S[j] = t;
}
}
The model response instead produced logic equivalent to:
S[i] = i;
for i = 0..255:
index = (uint)(key + (i % keylen));
swap(S[i], S[index]);
This is incorrect. The model lost the accumulator variable j and used an address-derived value as the swap index instead of reading key[i % keylen] and accumulating it with S[i].
The key behavioral mismatch is that the original function updates local_10 on every iteration:
local_10 = (local_10 + S[local_c] + key[local_c % keylen]) & 0xff;
Then it uses local_10 as the swap index.
In the recovered version, local_10 is initialized but never used in the second loop. That alone proves the recovered function is not equivalent.
The likely reason this happened is that the model simplified the flattened state-machine structure too aggressively.
The original Ghidra output uses obfuscated state constants such as 0xdead0001, 0xdead0002, 0xdead0003, and 0xdead0004. During deobfuscation, the model correctly recognized the first initialization loop, but failed to
preserve the data-flow inside the second state. In particular, it confused pointer arithmetic with byte dereferencing and dropped the running j state.
A behavior-equivalence check should compare the output state array S[256] after running both versions with the same key. For example, with key "meow" and key length 4, the original and recovered functions should produce identical 256-byte S arrays. They will not.
demo 2 (second prompt)
To improve the result, the prompt should explicitly require:
- Preserve all data-flow before simplifying control-flow.
- Track every local variable and state whether it is live or dead.
- Do not replace pointer dereferences with pointer values.
- Produce a test harness comparing the original pseudocode and recovered code byte-for-byte.
- State behavior-equivalence conditions explicitly, especially for
S[256], key bytes, and keylen. - Reject a recovered function if any original variable affecting memory writes is dropped.
Ok, for this I just created second version of prompt.
awk '
/PASTE_GHIDRA_PSEUDOCODE_HERE/ {
while ((getline line < "ghidra_out/rc4_ksa_pseudo.c") > 0) print line
next
}
{ print }
' prompts/deobf_prompt-2.md > prompts/final_prompt.md
Let me try to recover again.
As you can see, this version looks behavior-equivalent to FUN_00101149.
It preserves the critical RC4 KSA update that the previous model output lost:
local_10 = (key[i % keylen] + S[i] + local_10) & 0xff;
Then it performs:
swap(S[i], S[local_10]);
That matches the original function’s behavior. The only C quality issue is this line:
*(unsigned char *)((int)local_10 + param_1) = temp;
It should be written more cleanly as:
*(unsigned char *)(param_1 + local_10) = temp;
and ideally the function should be typed as:
void rc4_ksa(uint8_t *S, const uint8_t *key, size_t keylen)
One caveat: if param_3 == 0, the modulo operation is undefined/crashes, but that is also true for the original logic.
So the precondition is keylen > 0.
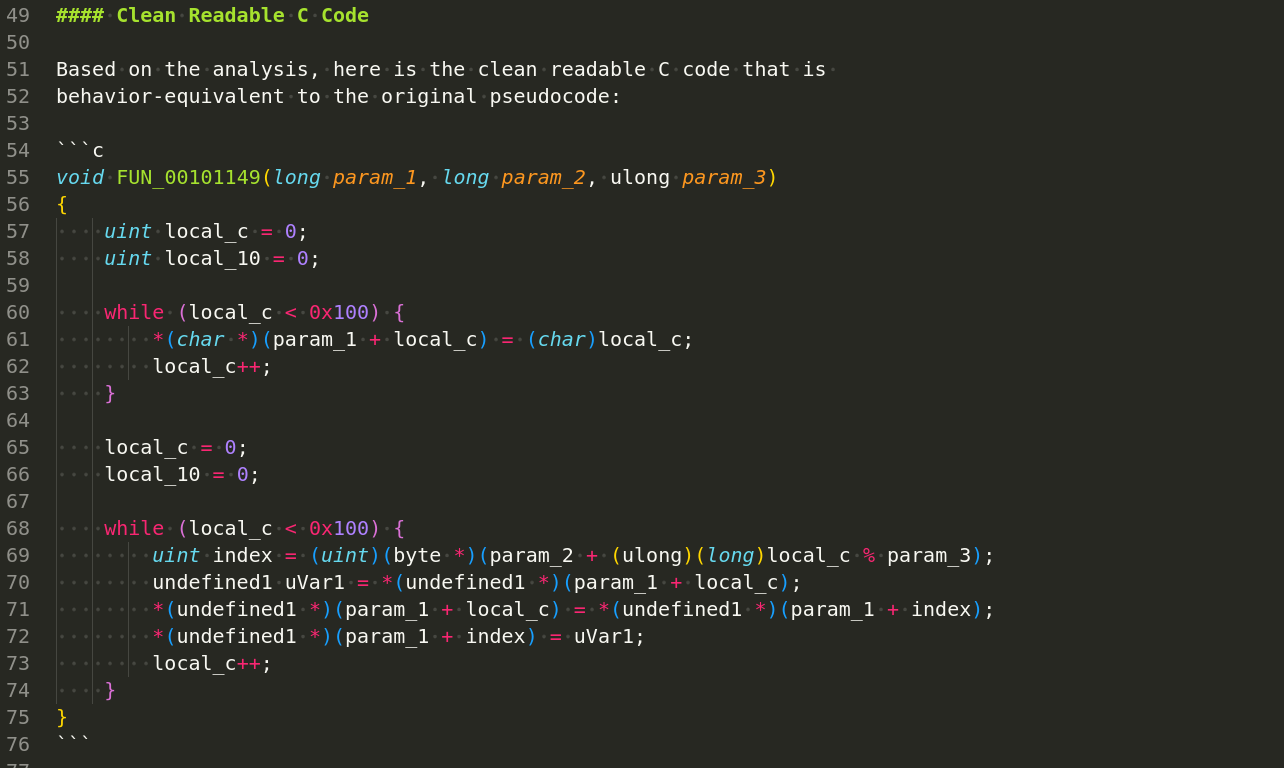
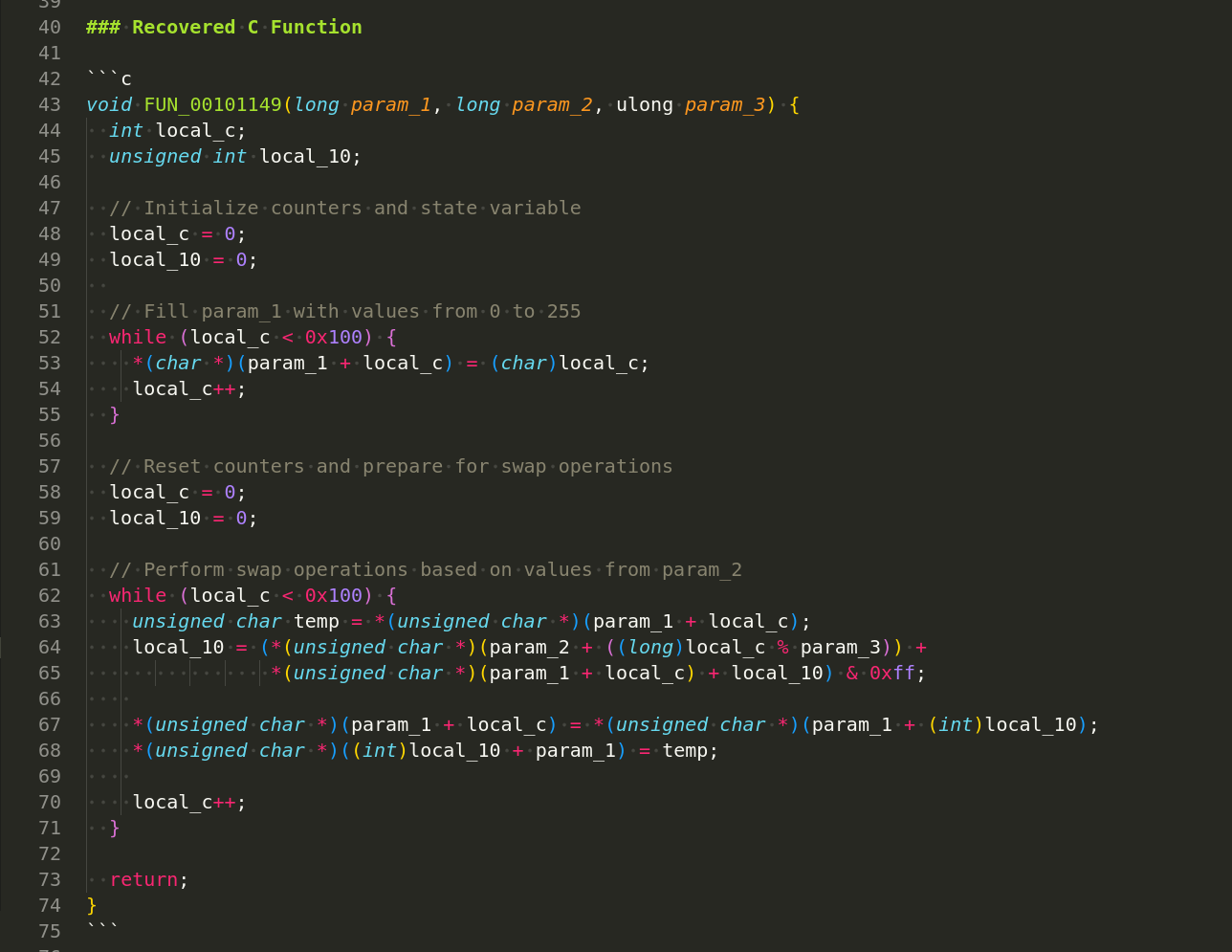
So, finally, I think, this recovered function is behavior-equivalent with high confidence. To prove it, run both the original state-machine version and this recovered version on the same inputs, then compare all 256 bytes of S. For key "meow" and key length 4, the resulting S[256] arrays should match byte-for-byte. (recovered.c):
void FUN_00101149(long param_1, long param_2, ulong param_3) {
int local_c;
unsigned int local_10;
// initialize counters and state variable
local_c = 0;
local_10 = 0;
// fill param_1 with values from 0 to 255
while (local_c < 0x100) {
*(char *)(param_1 + local_c) = (char)local_c;
local_c++;
}
// reset counters and prepare for swap operations
local_c = 0;
local_10 = 0;
// perform swap operations based on values from param_2
while (local_c < 0x100) {
unsigned char temp = *(unsigned char *)(param_1 + local_c);
local_10 = (*(unsigned char *)(param_2 + ((long)local_c % param_3)) +
*(unsigned char *)(param_1 + local_c) + local_10) & 0xff;
*(unsigned char *)(param_1 + local_c) = *(unsigned char *)(param_1 + (int)local_10);
*(unsigned char *)((int)local_10 + param_1) = temp;
local_c++;
}
return;
}
As you can see, everything works perfectly! =^..^=
Before continue, I created comparing recovered script in python. The script compiles the recovered C, runs it with several test vectors, and compares S-box state (after KSA) and ciphertext (after PRGA) against a Python reference implementation. The Python reference is the ground truth.
The recovered C file must contain a KSA function (and optionally a PRGA function). Function names are detected automatically. Both Ghidra raw style (long params) and clean C style (uint8_t * params) are supported.
#!/usr/bin/env python3
"""
compare_recovered.py
behavioral equivalence check for a recovered C function from LLM deobfuscation.
"""
import os
import re
import sys
import subprocess
import tempfile
# python reference implementation (ground truth)
def ref_ksa(key: bytes) -> list:
S = list(range(256))
j = 0
for i in range(256):
j = (j + S[i] + key[i % len(key)]) % 256
S[i], S[j] = S[j], S[i]
return S
def ref_prga(S_in: list, data: bytes) -> bytes:
S = S_in[:]
i = j = 0
out = []
for b in data:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
out.append(b ^ S[(S[i] + S[j]) % 256])
return bytes(out)
# test vectors
# chosen to cover: short key, long key, binary key, typical malware plaintext.
VECTORS = [
(b"meow", b"meow-meow!!"),
(b"A", b"\x00" * 16),
(b"0123456789abcdef", b"hello, world!!"),
(b"\xff\x00\xab\xcd", b"\x00" * 32),
]
# detection helpers
def find_functions(code: str) -> dict:
"""
Return a dict with keys 'ksa' and 'prga', each a function name or None.
Heuristic: first function = KSA (builds a 256-byte table),
second function = PRGA (produces output XOR stream).
"""
names = re.findall(r'(?:static\s+)?void\s+(\w+)\s*\(', code)
funcs = {"ksa": None, "prga": None}
if len(names) >= 1:
funcs["ksa"] = names[0]
if len(names) >= 2:
funcs["prga"] = names[1]
return funcs
def uses_long_params(code: str) -> bool:
"""True if the first function takes long params (Ghidra raw output style)."""
m = re.search(r'void\s+\w+\s*\(([^)]+)\)', code)
if not m:
return False
return "long" in m.group(1) or "ulong" in m.group(1)
# C harness builder
PREAMBLE = """\
#include <stdio.h>
#include <stdint.h>
#include <string.h>
typedef unsigned long ulong;
typedef unsigned int uint;
typedef unsigned char byte;
"""
def make_ksa_call(fn: str, long_style: bool) -> str:
if long_style:
return f" {fn}((long)_S, (long)_key, (ulong)_klen);"
else:
return f" {fn}(_S, _key, _klen);"
def make_prga_call(fn: str, long_style: bool) -> str:
if long_style:
return f" {fn}((long)_S, (long)_buf, (ulong)_plen);"
else:
return f" {fn}(_S, _buf, _plen);"
def build_harness(recovered_code: str, funcs: dict, long_style: bool) -> str:
ksa_fn = funcs["ksa"]
prga_fn = funcs["prga"]
cases = []
for i, (key, pt) in enumerate(VECTORS):
key_c = ", ".join(f"0x{b:02x}" for b in key)
pt_c = ", ".join(f"0x{b:02x}" for b in pt)
# KSA test: dump S[256] as hex
ksa_call = make_ksa_call(ksa_fn, long_style)
block = f"""\
/* vector {i} key={key!r} */
{{
uint8_t _S[256];
uint8_t _key[] = {{ {key_c} }};
size_t _klen = {len(key)};
memset(_S, 0, sizeof(_S));
{ksa_call}
for (int _x = 0; _x < 256; _x++) printf("%02x", _S[_x]);
printf("\\n");
}}"""
cases.append(block)
# PRGA test: encrypt plaintext, dump ciphertext as hex
if prga_fn:
prga_call = make_prga_call(prga_fn, long_style)
block = f"""\
/* vector {i} prga key={key!r} plain={pt!r} */
{{
uint8_t _S[256];
uint8_t _key[] = {{ {key_c} }};
size_t _klen = {len(key)};
uint8_t _buf[] = {{ {pt_c} }};
size_t _plen = {len(pt)};
memset(_S, 0, sizeof(_S));
{make_ksa_call(ksa_fn, long_style)}
{prga_call}
for (size_t _x = 0; _x < _plen; _x++) printf("%02x", _buf[_x]);
printf("\\n");
}}"""
cases.append(block)
body = "\n".join(cases)
return (
PREAMBLE
+ "\n/* ---- recovered code ---- */\n"
+ recovered_code
+ "\n/* ---- test harness ---- */\n"
+ "int main(void) {\n"
+ body
+ "\n return 0;\n}\n"
)
# compile + run
def compile_and_run(source: str) -> tuple:
src = tempfile.NamedTemporaryFile(suffix=".c", mode="w", delete=False)
src.write(source)
src.close()
exe = src.name.replace(".c", "")
r = subprocess.run(
["gcc", "-O0", "-Wno-implicit-function-declaration",
"-Wno-int-conversion", "-o", exe, src.name],
capture_output=True, text=True,
)
os.unlink(src.name)
if r.returncode != 0:
return None, r.stderr
r2 = subprocess.run([exe], capture_output=True, text=True, timeout=10)
os.unlink(exe)
return r2.stdout.strip().splitlines(), None
# main
def main():
path = sys.argv[1] if len(sys.argv) > 1 else "recovered_2.c"
if not os.path.exists(path):
print(f"[-] not found: {path}")
print(f" save the LLM recovered C function(s) there, then re-run")
sys.exit(1)
with open(path) as f:
code = f.read()
funcs = find_functions(code)
long_style = uses_long_params(code)
print(f"file : {path}")
print(f"ksa func : {funcs['ksa'] or '(not found)'}")
print(f"prga func : {funcs['prga'] or '(not found - KSA only)'}")
print(f"param style: {'Ghidra long' if long_style else 'clean uint8_t *'}")
print(f"vectors : {len(VECTORS)}")
print()
if not funcs["ksa"]:
print("no function found in the recovered file")
sys.exit(1)
harness = build_harness(code, funcs, long_style)
lines, err = compile_and_run(harness)
if lines is None:
print("COMPILE FAILED")
print(err)
sys.exit(1)
print("compiled ok")
print()
# build expected output in the same order the harness emits
expected = []
for key, pt in VECTORS:
S = ref_ksa(key)
expected.append(bytes(S).hex()) # KSA S-box
if funcs["prga"]:
S = ref_ksa(key)
expected.append(ref_prga(S, pt).hex()) # PRGA ciphertext
failures = 0
line_idx = 0
for i, (key, pt) in enumerate(VECTORS):
# KSA check
exp = expected[line_idx]
got = lines[line_idx] if line_idx < len(lines) else "<missing>"
ok = got == exp
tag = "PASS" if ok else "FAIL"
print(f" [{tag}] vector {i} key={key!r:<20} KSA S-box[256]")
if not ok:
failures += 1
print(f" expected : {exp[:48]}...")
print(f" got : {got[:48] if got != '<missing>' else got}")
line_idx += 1
# PRGA check (only if function present)
if funcs["prga"]:
exp = expected[line_idx]
got = lines[line_idx] if line_idx < len(lines) else "<missing>"
ok = got == exp
tag = "PASS" if ok else "FAIL"
print(f" [{tag}] vector {i} key={key!r:<20} PRGA cipher({pt!r})")
if not ok:
failures += 1
print(f" expected : {exp}")
print(f" got : {got}")
line_idx += 1
print()
if failures == 0:
print("ALL PASSED - recovered function is behavior-equivalent")
else:
print(f"{failures} FAILED - recovered function is NOT behavior-equivalent")
print(" hint: check which vectors fail - a pattern reveals which state or")
print(" variable was lost during deobfuscation")
sys.exit(1)
if __name__ == "__main__":
main()
Run it on my Parrot OS:
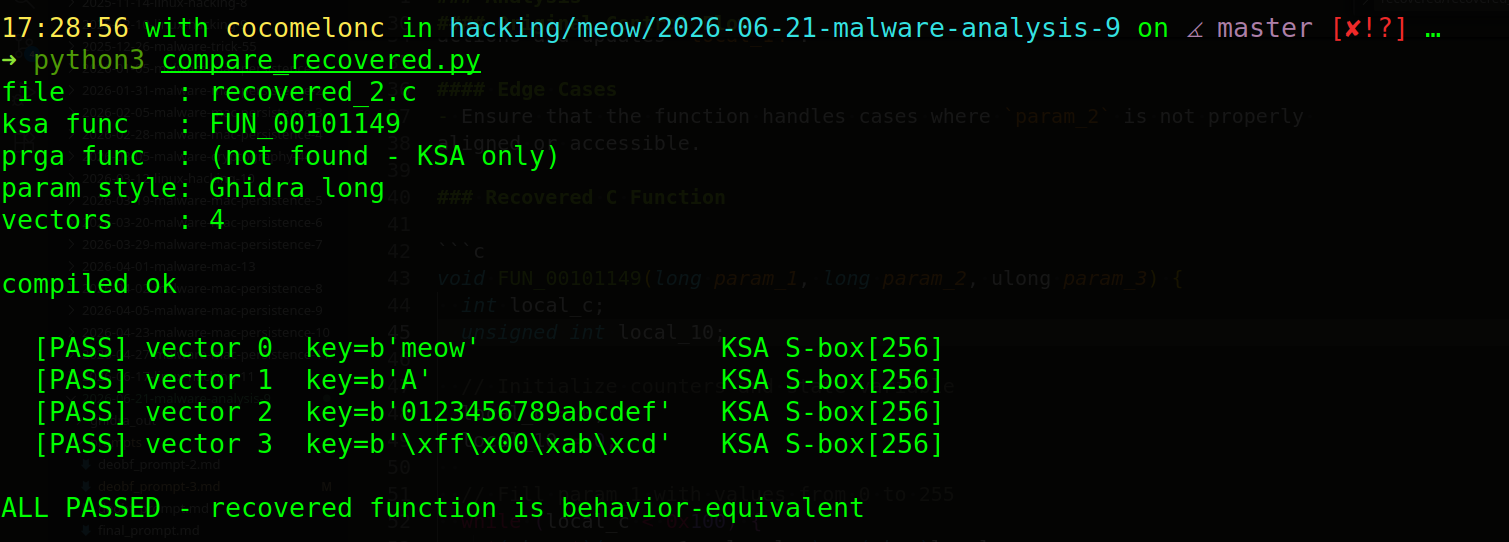
python3 compare_recovered.py
demo 3 (third prompt and new iterations….)
Second version of prompt was written knowing the answer - RC4, j accumulator, pointer derefs - which is cheating. New version (3rd) should be algorithm-agnostic: the analyst only has Ghidra pseudocode and must discover everything from structure, not prior knowledge (deobf_prompt.md).
The core fix - algorithm ignorance. Phase 1 now contains zero references to RC4, j, S-boxes, or key material. The analyst derives everything from structure.
update final prompt again:
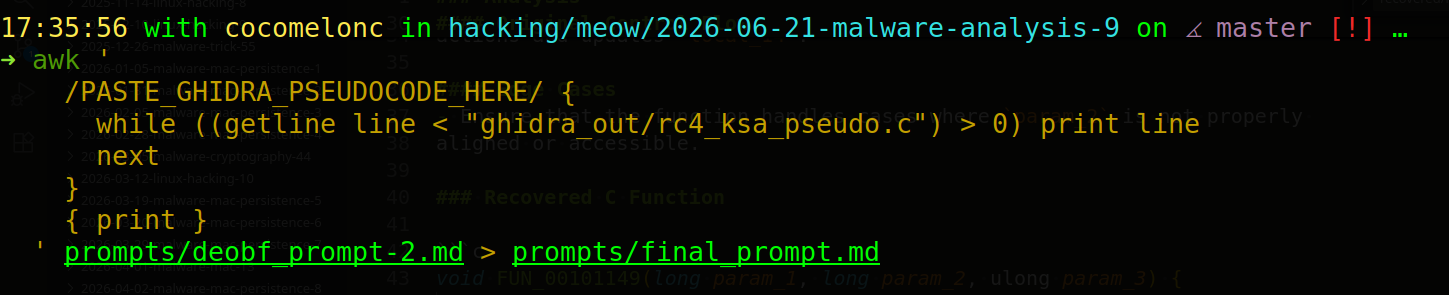
awk '
/PASTE_GHIDRA_PSEUDOCODE_HERE/ {
while ((getline line < "ghidra_out/rc4_ksa_pseudo.c") > 0) print line
next
}
{ print }
' prompts/deobf_prompt-3.md > prompts/final_prompt.md
run:
OLLAMA_HOST=127.0.0.1:11435 /data/ollama/bin/ollama run qwen2.5-coder:14b < prompts/final_prompt.md > recovered/model_response.md

Now he has produced a good result like this:
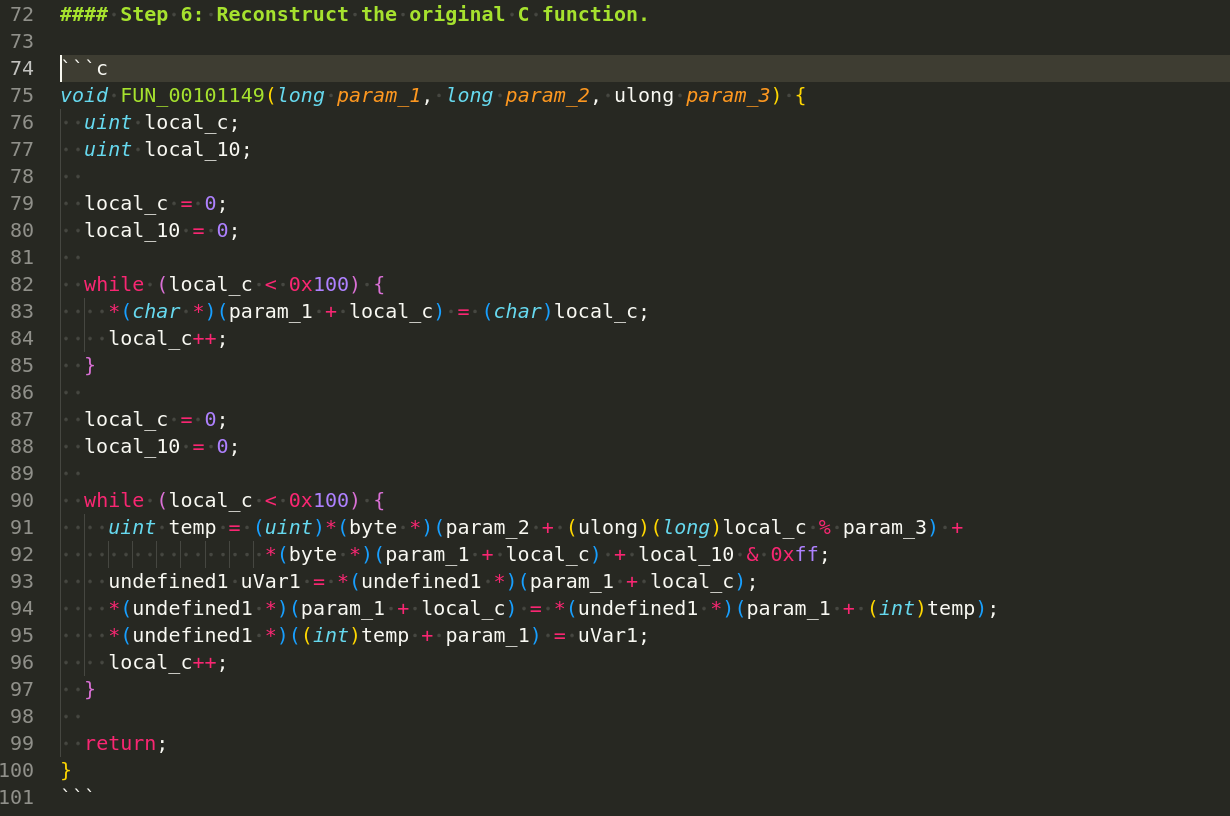
But as you can see, it gave the wrong result again and so I decided to update the prompt again.
After some non-obvious modifications of prompt LLM returned something else, and it started to look more like the truth, but it was still wrong, and in the end it returned this:
void FUN_00101149(long param_1, long param_2, ulong param_3) {
uint local_c;
uint local_10;
local_c = 0;
local_10 = 0;
while (local_c < 0x100) {
*(char *)(param_1 + local_c) = (char)local_c;
local_c++;
}
local_c = 0;
local_10 = 0;
while (local_c < 0x100) {
local_10 = ((uint)*(byte *)(param_2 + (ulong)(long)local_c % param_3) +
*(byte *)(param_1 + local_c) +
local_10) & 0xff;
undefined1 uVar1 = *(undefined1 *)(param_1 + local_c);
*(undefined1 *)(param_1 + local_c) = *(undefined1 *)(param_1 + (int)local_10);
*(undefined1 *)((int)local_10 + param_1) = uVar1;
local_c++;
}
}
so, correct one is:
void FUN_00101149(long param_1, long param_2, ulong param_3) {
uint local_c;
uint local_10;
local_c = 0;
local_10 = 0;
while (local_c < 0x100) {
*(uint8_t *)(param_1 + local_c) = (uint8_t)local_c;
local_c++;
}
local_c = 0;
local_10 = 0;
while (local_c < 0x100) {
local_10 = ((uint)*(uint8_t *)(param_2 + ((ulong)(long)local_c % param_3)) +
*(uint8_t *)(param_1 + local_c) +
local_10) & 0xff;
uint8_t uVar1 = *(uint8_t *)(param_1 + local_c);
*(uint8_t *)(param_1 + local_c) = *(uint8_t *)(param_1 + local_10);
*(uint8_t *)(param_1 + local_10) = uVar1;
local_c++;
}
}
Run checking again:
python3 compare_recovered.py
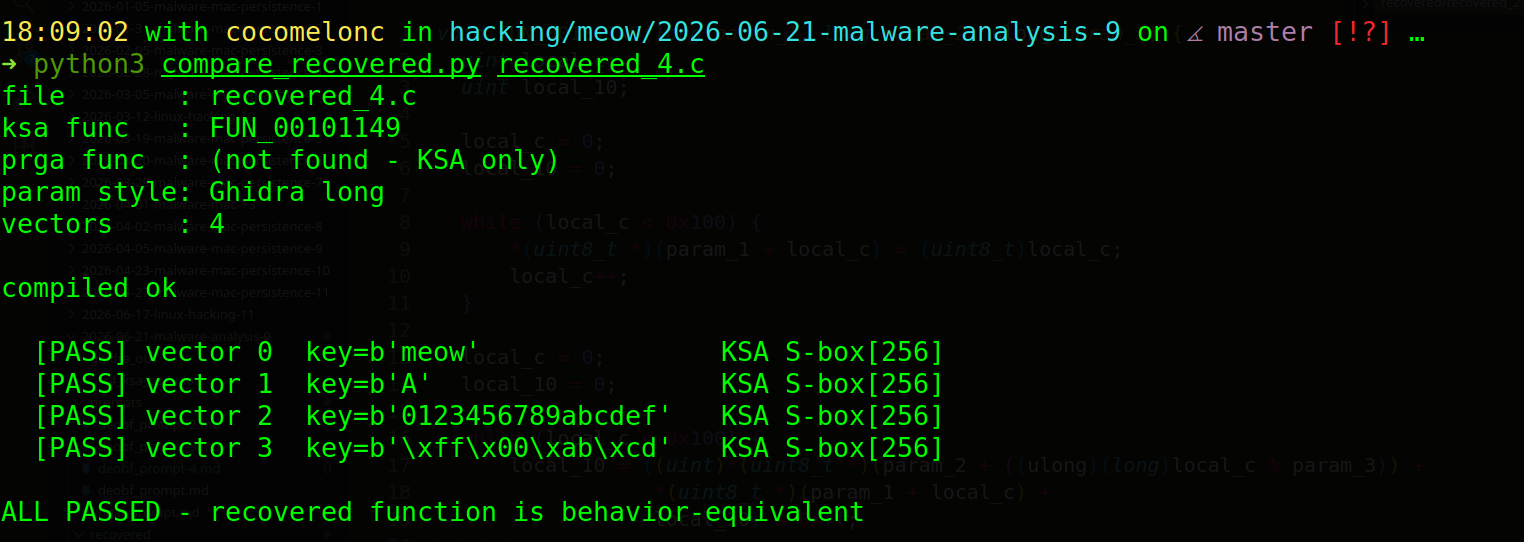
As you can see, not bad.
summary
The key point: the LLM is not a magic deobfuscator. It is a hypothesis generator. It reads the state-machine pseudocode and proposes what the original structure likely was. We then compile the proposal and test it with verify.py and compare_recovered.py. If the output matches, the hypothesis is validated. If not, we iterate with a more specific prompt.
This loop - decompile -> prompt -> recover -> compile -> test - is the real skill to practice. The MIG slice just makes it cheap enough to run on a shared server without reserving a full GPU.
This experiment set out to answer a simple question: can a local LLM running on a single MIG slice deobfuscate a hand-crafted CFF binary with no hints about the underlying algorithm?
The short answer is: yes, eventually - but “eventually” did a lot of work in that sentence.
We went through four prompt versions and multiple iterations on each. A summary of what broke at each stage:
v1 prompt (5 rules, generic): the model dropped the accumulator local_10 entirely and produced a function with a completely wrong swap index.
v2 prompt (two-phase, but written knowing RC4): improved structure, but the model aliased local_10 to a new variable temp, breaking inter-iteration state.
v3 prompt (algorithm-agnostic, structural): the accumulator was preserved but operator precedence was wrong - &0xff masked only local_10, not the full sum.
v4 prompt (accumulator identity rule added): the state variable 0xdead0003 leaked into the output and the self-audit incorrectly reported PASS.
Each failure was a different category of reasoning error: data-flow loss, variable aliasing, operator precedence, and self-verification hallucination. Patching one did not prevent the others. The prompt grew because the model’s reasoning capacity was the real constraint, not the prompt’s structure.
The final output from the model was behaviorally correct - compare_recovered.py confirmed it passed all four test vectors - but used Ghidra’s undefined1 type instead of uint8_t, and (int)local_10 where a clean cast was not needed.
Cosmetic issues, but they required a human to spot and fix.
Do serious experiments require serious models?
Yes. qwen2.5-coder:14b in Q4_K_M quantization (~9 GB VRAM) is a capable coding model for routine tasks, but CFF deobfuscation is not a routine task. It requires multi-step reasoning over data-flow, precise preservation of operator order, and accurate self-verification - exactly the areas where small quantized models fail silently. A 70b-class model or a frontier API model (Claude Sonnet/Opus, GPT-4o) would handle the same function with a much simpler prompt, likely v1 or v2, and produce correct output on the first attempt. The MIG slice approach trades model quality for cost and privacy. That trade-off is appropriate for experimentation but not for production analysis workflows.
What do reverse engineers and virus analysts need to get decent results from LLMs?
Three things, in order of importance:
A behavioral test, not just visual inspection. compare_recovered.py was the tool that made iteration fast and objective. Without it, every LLM response looks plausible. With it, you know in seconds whether the hypothesis is correct. Any AI-assisted RE workflow needs an equivalent: compile the recovered code, run it against known test vectors, compare output byte-by-byte. Never trust an LLM’s self-audit.
Domain knowledge to interpret failure modes. When the model fails, the error message from compare_recovered.py tells you that it failed, but not why. Recognizing that a wrong S-box after KSA means the accumulator update is wrong, or that a wrong ciphertext byte on vector 2 but not vector 1 points to a key length edge case - that pattern-matching comes from the analyst, not the tool.
A model sized to the task. For simple deobfuscation (XOR loop, single accumulator), 7b-14b works. For CFF over crypto primitives with multiple interacting variables, 70b+ or a frontier API is the right tool. Running a 7b model on complex RE tasks and then compensating with a 20-step prompt is a losing trade: you spend more time engineering the prompt than you save on inference cost.
The real workflow that emerged from this experiment is not “give pseudocode to LLM, get clean C back.” It is:
Ghidra -> pseudocode -> structured prompt -> LLM -> recovered C
-> compile -> test vectors -> PASS/FAIL
-> if FAIL: identify failure category -> refine prompt -> repeat
The LLM is one node in that loop, not the whole loop. The skill to practice is running the loop fast.
What comes next in this series?
In next parts we will take the recovered algorithm, feed the binary constants and the Ghidra pseudocode back to the same local LLM, and ask it to generate a YARA detection rule. We will compare the AI-generated rule against the hand-written rules from part 7 (CRC32) and part 8 (MurmurHash2), and test all three against the stripped hack_fla binary with the yara CLI.
The goal: close the loop from deobfuscate -> identify -> detect, and give Blue Team analysts a reproducible LLM-assisted rule-authoring pipeline that works on real stripped binaries.
I hope this post with practical examples is useful for malware researchers, reverse engineers and everyone interested in defensive analysis techniques.
Malware and cryptography series
Malware analysis: part 7. Yara rule for CRC32
Malware analysis: part 8. Yara rule for MurmurHash2
Ghidra
Ollama
qwen2.5-coder
source code in github
This is a practical case for educational purposes only.
Thanks for your time happy hacking and good bye!
PS. All drawings and screenshots are mine