Malware and cryptography 45 - Shamir Secret Sharing. Simple C example.
﷽
Hello, cybersecurity enthusiasts and white hackers!
In previous posts of the malware and cryptography series, we mostly looked at payload hiding: block ciphers, stream ciphers, S-boxes, DFT tricks, and other ways to transform bytes before executing or storing them. Today I want to look at a different problem: how do we split a secret so that no single person, file, or server has enough information to recover it?
This is where Shamir’s Secret Sharing becomes useful.
The idea is elegant: split a secret into N shares, choose a threshold K, and make sure that:
any K shares reconstruct the original secret;
any K-1 shares reveal nothing about it.
This is not “encrypt with password A and password B”. It is not XORing chunks together. It is a real threshold construction with information-theoretic secrecy.
For malware research and red team tooling, this idea appears in many places:
- split a decryption key between multiple operators;
- require several implants or stages to cooperate before revealing a payload;
- avoid storing the full secret in one binary or one config file;
- build training labs for blue teamers to understand distributed key material;
- study how advanced tooling can hide operational secrets without inventing new crypto.
In this post we will implement a tiny proof-of-concept in pure C for Linux. It also cross-compiles with MinGW for Windows. No OpenSSL, no external libraries, no Python in the implementation. Python is used only later for plotting benchmark results.
This is educational/research code only. Do not use it for production secret storage without a serious security review.
Shamir Secret Sharing
Shamir’s Secret Sharing was introduced by Adi Shamir in 1979 in the paper How to Share a Secret. The construction is based on a simple mathematical fact:
A polynomial of degree \(K-1\) is uniquely determined by \(K\) distinct points.
For example, a line needs two points, a parabola needs three points, and so on.
In our case, the secret is the value of the polynomial at zero:
\[f(0) = s\]To split a secret byte \(s\) with threshold \(K\), we build a random polynomial:
\[f(x) = s + a_1 x + a_2 x^2 + \dots + a_{K-1}x^{K-1}\]where \(a_1, a_2, \dots, a_{K-1}\) are random coefficients.
Then we evaluate this polynomial at non-zero points:
\[share_i = (x_i, f(x_i))\]For example:
share 1: x = 1, y = f(1)
share 2: x = 2, y = f(2)
share 3: x = 3, y = f(3)
...
The secret is not stored directly in any share. It is hidden as the value of the polynomial at \(x=0\).
why GF(2^8)?
In this implementation, I split files byte-by-byte. That means every byte is a value from 0 to 255. It is tempting to do math modulo 256, but \(\mathbb{Z}/256\mathbb{Z}\) is not a field. Some non-zero values do not have multiplicative inverses. For Shamir reconstruction we need division, so we need a field.
The natural byte-sized field is:
\[\mathrm{GF}(2^8)\]I use the same irreducible polynomial used by AES:
\[x^8 + x^4 + x^3 + x + 1\]In hexadecimal form, this is:
0x11b
In C code, after shifting a byte left, the high bit overflow is reduced with 0x1b:
if (hi) a ^= 0x1bU;
This is the standard AES byte-field reduction logic.
Addition in \(\mathrm{GF}(2^8)\) is XOR:
\[a + b = a \oplus b\]Subtraction is the same operation, because the field has characteristic two:
\[a - b = a + b = a \oplus b\]This is why Lagrange interpolation in this field looks a little unusual but remains clean.
Lagrange reconstruction
Given any \(K\) shares:
\[(x_1, y_1), (x_2, y_2), \dots, (x_K, y_K)\]we reconstruct the secret by evaluating the interpolation polynomial at zero:
\[f(0) = \sum_{i=1}^{K} y_i \cdot \ell_i(0)\]where:
\[\ell_i(0) = \prod_{j=1, j \neq i}^{K} \frac{0 - x_j}{x_i - x_j}\]In \(\mathrm{GF}(2^8)\), subtraction is XOR, so:
\[0 - x_j = x_j\]and:
\[x_i - x_j = x_i \oplus x_j\]Therefore the formula used in the code is:
\[f(0) = \bigoplus_{i=1}^{K} y_i \cdot \prod_{j=1, j \neq i}^{K} \frac{x_j}{x_i \oplus x_j}\]This is exactly what the interpolate_at_zero function does.
tiny file format
This PoC writes every share as a tiny text header plus raw binary bytes:
TINY-SHAMIR-V1 k=3 n=5 x=1 len=1234
<binary share bytes>
where:
kis the threshold;nis the total number of generated shares;xis the share coordinate;lenis the original secret length;- the rest of the file is one byte per original secret byte.
There is no IETF RFC for this exact raw container. The cryptographic construction is Shamir’s original scheme; the field arithmetic uses the AES/FIPS-197 byte field; the container is intentionally small and documented for research.
practical example
Let’s start from simple C example. The project structure is simple: only one C file is required:
tree -h ./
GF multiplication
The first important function is multiplication in \(\mathrm{GF}(2^8)\):
static uint8_t gf_mul_slow(uint8_t a, uint8_t b) {
uint8_t p = 0;
for (int i = 0; i < 8; i++) {
if (b & 1U) p ^= a;
uint8_t hi = (uint8_t)(a & 0x80U);
a = (uint8_t)(a << 1);
if (hi) a ^= 0x1bU;
b = (uint8_t)(b >> 1);
}
return p;
}
This is the classic “Russian peasant multiplication” style used in AES implementations:
- if the low bit of
bis set, XOR the currentainto the product; - multiply
aby \(x\), implemented as left shift; - if the high bit overflowed, reduce by the AES polynomial;
- shift
bright and continue.
This function is simple, but calling it for every multiplication would be slow. So we build log/exp tables:
static void gf_init(void) {
uint8_t x = 1;
for (int i = 0; i < 255; i++) {
gf_exp[i] = x;
gf_log[x] = (uint8_t)i;
x = gf_mul_slow(x, 0x03U);
}
for (int i = 255; i < 512; i++) gf_exp[i] = gf_exp[i - 255];
gf_log[0] = 0;
gf_ready = 1;
}
The element 0x03 is primitive in this field. We generate all non-zero field elements and map:
value -> logarithm
logarithm -> value
Then multiplication becomes:
\[a \cdot b = \alpha^{\log(a) + \log(b)}\]implemented as:
static uint8_t gf_mul(uint8_t a, uint8_t b) {
if (!gf_ready) gf_init();
if (a == 0 || b == 0) return 0;
return gf_exp[gf_log[a] + gf_log[b]];
}
Division is the same idea:
\[a / b = \alpha^{\log(a) - \log(b)}\]static uint8_t gf_div(uint8_t a, uint8_t b) {
if (!gf_ready) gf_init();
if (b == 0) die("division by zero in GF(256)");
if (a == 0) return 0;
return gf_exp[gf_log[a] + 255 - gf_log[b]];
}
The + 255 avoids negative values because the non-zero multiplicative group has size 255.
polynomial evaluation
Each byte gets its own random polynomial. We evaluate it with Horner’s method:
static uint8_t poly_eval(const uint8_t *coef, int k, uint8_t x) {
uint8_t y = coef[k - 1];
for (int i = k - 2; i >= 0; i--) {
y = (uint8_t)(gf_mul(y, x) ^ coef[i]);
}
return y;
}
For a 3-of-5 split, k = 3, so the polynomial is:
where:
c0 is the secret byte;
c1 and c2 are random bytes.
Horner form evaluates it like this:
\[f(x) = ((c_2x) \oplus c_1)x \oplus c_0\]This is compact and avoids explicitly computing every power of \(x\).
splitting
The split command does this:
for (uint64_t p = 0; p < len; p++) {
coef[0] = secret[p];
if (secure_random(coef + 1, (size_t)(k - 1)) != 0) die("random source failed");
for (int x = 1; x <= n; x++) {
rows[(size_t)(x - 1) * (size_t)len + (size_t)p] = poly_eval(coef, k, (uint8_t)x);
}
}
This is the heart of the implementation.
For every byte position p:
- put the original secret byte into
coef[0]; - generate
k-1random coefficients; - evaluate the polynomial at
x = 1, 2, ..., n; - store each result into the matching share row.
The important detail: the random polynomial is generated once per secret byte, then evaluated for all shares. If you accidentally generate new random coefficients separately for each share, reconstruction becomes impossible because the shares no longer lie on the same polynomial.
what about recovery?
Recovery reads at least K shares and reconstructs each byte independently:
for (uint64_t p = 0; p < len; p++)
secret[p] = interpolate_at_zero(shares, k, p);
The interpolation function is:
static uint8_t interpolate_at_zero(const share_t *shares, int k, uint64_t pos) {
uint8_t acc = 0;
for (int i = 0; i < k; i++) {
uint8_t xi = shares[i].x;
uint8_t yi = shares[i].y[pos];
uint8_t num = 1;
uint8_t den = 1;
for (int j = 0; j < k; j++) {
if (i == j) continue;
uint8_t xj = shares[j].x;
num = gf_mul(num, xj);
den = gf_mul(den, (uint8_t)(xi ^ xj));
}
acc ^= gf_mul(yi, gf_div(num, den));
}
return acc;
}
For each share \(i\), it builds the Lagrange basis coefficient:
\[\prod_{j \neq i} \frac{x_j}{x_i \oplus x_j}\]Then it multiplies this coefficient by the share byte \(y_i\), XORs all terms together, and obtains \(f(0)\).
parser caveat
One subtle bug is worth discussing. Since the share file has a text header followed by binary data, do not parse the header with fscanf(... "\n"). In scanf, whitespace in the format string consumes arbitrary following whitespace. But binary share data can start with 0x09, 0x0a, 0x0d, or 0x20. If scanf eats the first binary byte, the share becomes “short”.
The safe approach is:
if (!fgets(header, sizeof(header), f)) die("bad share header");
if (sscanf(header, "%63s k=%hhu n=%hhu x=%hhu len=%" SCNu64,
magic, &s.k, &s.n, &s.x, &s.len) != 5) {
die("bad share header");
}
Read exactly one line with fgets, parse that line with sscanf, and then switch to raw fread.
This is one of those bugs that only appears when you start testing on a real dataset.
benchmark dataset
For research I generated a dataset with many files:
1200 files
2.4049 GiB total
64 KiB smallest file
31 MiB largest file
Then I ran the plotting helper:
python3 plot_dataset.py ./tiny-shamir ./dataset_1000 3 5 results_1000.csv results_1000.png
The helper does:
- split every file as
3-of-5; - recover from the first three shares;
- compare SHA-256 of original and recovered file;
- write timings to CSV;
- plot split/recover time.

As expected, split time grows roughly linearly with file size. Recovery is cheaper for 3-of-5, because reconstruction uses only K shares, while splitting evaluates the polynomial for all N shares.
mathematical proof
Why does this work?
A polynomial of degree \(K-1\) over a field is uniquely determined by \(K\) distinct points. In our scheme, the secret byte is:
\[s = f(0)\]Every share gives one point on the polynomial:
\[(x_i, y_i) = (x_i, f(x_i))\]Given \(K\) distinct points, Lagrange interpolation reconstructs the exact polynomial:
\[f(x) = \sum_{i=1}^{K} y_i \ell_i(x)\]where:
\[\ell_i(x) = \prod_{j \neq i} \frac{x - x_j}{x_i - x_j}\]Set \(x=0\), and you get:
\[f(0) = \sum_{i=1}^{K} y_i \prod_{j \neq i} \frac{-x_j}{x_i - x_j}\]In \(\mathrm{GF}(2^8)\), minus is the same as plus, so:
\[-x_j = x_j\]and:
\[x_i - x_j = x_i \oplus x_j\]which gives the implementation formula:
\[f(0) = \bigoplus_{i=1}^{K} y_i \cdot \prod_{j \neq i} \frac{x_j}{x_i \oplus x_j}\]Why do \(K-1\) shares reveal nothing?
With \(K-1\) known points, for every possible secret byte \(s’\), there exists exactly one polynomial of degree at most \(K-1\) that passes through:
- the \(K-1\) known share points;
- the point \((0, s’)\).
So every candidate secret byte remains possible:
\[\Pr[\text{secret}=s' \mid K-1\ \text{shares}] = \frac{1}{256}\]for every \(s’\) in a byte field, assuming the coefficients are uniformly random.
This is information-theoretic secrecy. It does not depend on computational hardness.
full source code
So, full source code is looks like this (tiny_shamir.c):
/*
* tiny_shamir.c
* Tiny Shamir threshold secret sharing PoC over GF(2^8).
* This is Shamir's Secret Sharing in a byte field. Each input byte becomes
* the constant term of a random degree K-1 polynomial over GF(256). Share X
* stores f(X) for every byte. Any K unique shares reconstruct f(0), which is
* the original secret. K-1 shares reveal no information in the ideal model.
*
* There is no single IETF RFC that defines this raw file format. The field
* arithmetic uses the standard AES polynomial x^8 + x^4 + x^3 + x + 1
* (0x11b), as specified for GF(2^8) arithmetic in FIPS-197. The container
* below is intentionally small and documented in code for research.
*
* author: cocomelonc
* educational/research PoC only.
* https://cocomelonc.github.io
*/
#ifndef _WIN32
#define _POSIX_C_SOURCE 200809L
#endif
#include <errno.h>
#include <inttypes.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#ifdef _WIN32
#include <windows.h>
#include <wincrypt.h>
#endif
#define TINY_MAGIC "TINY-SHAMIR-V1"
#define MAX_SHARES 255
#define MAX_PATH_LEN 4096
typedef struct {
uint8_t k;
uint8_t n;
uint8_t x;
uint64_t len;
uint8_t *y;
} share_t;
static uint8_t gf_exp[512];
static uint8_t gf_log[256];
static int gf_ready = 0;
static void die(const char *msg) {
fprintf(stderr, "error: %s\n", msg);
exit(1);
}
static void *xmalloc(size_t n) {
void *p = malloc(n ? n : 1);
if (!p) die("out of memory");
return p;
}
static uint8_t gf_mul_slow(uint8_t a, uint8_t b) {
uint8_t p = 0;
for (int i = 0; i < 8; i++) {
if (b & 1U) p ^= a;
uint8_t hi = (uint8_t)(a & 0x80U);
a = (uint8_t)(a << 1);
if (hi) a ^= 0x1bU;
b = (uint8_t)(b >> 1);
}
return p;
}
static void gf_init(void) {
uint8_t x = 1;
for (int i = 0; i < 255; i++) {
gf_exp[i] = x;
gf_log[x] = (uint8_t)i;
x = gf_mul_slow(x, 0x03U);
}
for (int i = 255; i < 512; i++) gf_exp[i] = gf_exp[i - 255];
gf_log[0] = 0;
gf_ready = 1;
}
static uint8_t gf_mul(uint8_t a, uint8_t b) {
if (!gf_ready) gf_init();
if (a == 0 || b == 0) return 0;
return gf_exp[gf_log[a] + gf_log[b]];
}
static uint8_t gf_div(uint8_t a, uint8_t b) {
if (!gf_ready) gf_init();
if (b == 0) die("division by zero in GF(256)");
if (a == 0) return 0;
return gf_exp[gf_log[a] + 255 - gf_log[b]];
}
static uint8_t poly_eval(const uint8_t *coef, int k, uint8_t x) {
uint8_t y = coef[k - 1];
for (int i = k - 2; i >= 0; i--) {
y = (uint8_t)(gf_mul(y, x) ^ coef[i]);
}
return y;
}
static uint8_t interpolate_at_zero(const share_t *shares, int k, uint64_t pos) {
uint8_t acc = 0;
for (int i = 0; i < k; i++) {
uint8_t xi = shares[i].x;
uint8_t yi = shares[i].y[pos];
uint8_t num = 1;
uint8_t den = 1;
for (int j = 0; j < k; j++) {
if (i == j) continue;
uint8_t xj = shares[j].x;
num = gf_mul(num, xj);
den = gf_mul(den, (uint8_t)(xi ^ xj));
}
acc ^= gf_mul(yi, gf_div(num, den));
}
return acc;
}
static int secure_random(uint8_t *buf, size_t len) {
#ifdef _WIN32
static HCRYPTPROV h = 0;
if (!h) {
if (!CryptAcquireContextA(&h, NULL, NULL, PROV_RSA_FULL, CRYPT_VERIFYCONTEXT)) return -1;
}
while (len > 0) {
DWORD chunk = len > 0x40000000U ? 0x40000000U : (DWORD)len;
if (!CryptGenRandom(h, chunk, buf)) return -1;
buf += chunk;
len -= chunk;
}
return 0;
#else
static FILE *rng = NULL;
if (!rng) rng = fopen("/dev/urandom", "rb");
if (!rng) return -1;
return fread(buf, 1, len, rng) == len ? 0 : -1;
#endif
}
static uint8_t *read_file(const char *path, uint64_t *len) {
FILE *f = fopen(path, "rb");
if (!f) {
perror(path);
exit(1);
}
if (fseek(f, 0, SEEK_END) != 0) die("fseek failed");
long sz = ftell(f);
if (sz < 0) die("ftell failed");
rewind(f);
uint8_t *buf = xmalloc((size_t)sz);
if (sz && fread(buf, 1, (size_t)sz, f) != (size_t)sz) die("read failed");
fclose(f);
*len = (uint64_t)sz;
return buf;
}
static void write_file(const char *path, const uint8_t *buf, uint64_t len) {
FILE *f = fopen(path, "wb");
if (!f) {
perror(path);
exit(1);
}
if (len && fwrite(buf, 1, (size_t)len, f) != (size_t)len) die("write failed");
fclose(f);
}
static void write_share(const char *path, uint8_t k, uint8_t n, uint8_t x,
const uint8_t *y, uint64_t len) {
FILE *f = fopen(path, "wb");
if (!f) {
perror(path);
exit(1);
}
fprintf(f, "%s k=%u n=%u x=%u len=%" PRIu64 "\n", TINY_MAGIC, k, n, x, len);
if (len && fwrite(y, 1, (size_t)len, f) != (size_t)len) die("share write failed");
fclose(f);
}
static share_t read_share(const char *path) {
share_t s;
char magic[64];
char header[256];
memset(&s, 0, sizeof(s));
FILE *f = fopen(path, "rb");
if (!f) {
perror(path);
exit(1);
}
if (!fgets(header, sizeof(header), f)) die("bad share header");
if (sscanf(header, "%63s k=%hhu n=%hhu x=%hhu len=%" SCNu64,
magic, &s.k, &s.n, &s.x, &s.len) != 5) {
die("bad share header");
}
if (strcmp(magic, TINY_MAGIC) != 0) die("bad share magic");
if (s.k < 2 || s.n < s.k || s.x == 0) die("bad share parameters");
s.y = xmalloc((size_t)s.len);
if (s.len && fread(s.y, 1, (size_t)s.len, f) != (size_t)s.len) die("short share");
fclose(f);
return s;
}
static void validate_shares(const share_t *shares, int count) {
if (count < 1) die("no shares");
uint8_t k = shares[0].k;
uint8_t n = shares[0].n;
uint64_t len = shares[0].len;
if (count < k) die("not enough shares for threshold");
for (int i = 0; i < count; i++) {
if (shares[i].k != k || shares[i].n != n || shares[i].len != len) {
die("shares belong to different split sets");
}
for (int j = i + 1; j < count; j++) {
if (shares[i].x == shares[j].x) die("duplicate share x-coordinate");
}
}
}
static void cmd_split(int argc, char **argv) {
if (argc != 6) die("usage: split <K> <N> <secret.bin> <share-prefix>");
int k = atoi(argv[2]);
int n = atoi(argv[3]);
if (k < 2 || n < k || n > MAX_SHARES) die("need 2 <= K <= N <= 255");
uint64_t len = 0;
uint8_t *secret = read_file(argv[4], &len);
uint8_t *coef = xmalloc((size_t)k);
uint8_t *rows = xmalloc((size_t)n * (size_t)len);
for (uint64_t p = 0; p < len; p++) {
coef[0] = secret[p];
if (secure_random(coef + 1, (size_t)(k - 1)) != 0) die("random source failed");
for (int x = 1; x <= n; x++) {
rows[(size_t)(x - 1) * (size_t)len + (size_t)p] = poly_eval(coef, k, (uint8_t)x);
}
}
for (int x = 1; x <= n; x++) {
char path[MAX_PATH_LEN];
snprintf(path, sizeof(path), "%s.%03d", argv[5], x);
write_share(path, (uint8_t)k, (uint8_t)n, (uint8_t)x,
rows + (size_t)(x - 1) * (size_t)len, len);
printf("wrote %s\n", path);
}
free(rows);
free(coef);
free(secret);
}
static void cmd_recover(int argc, char **argv) {
if (argc < 5) die("usage: recover <out.bin> <share1> <share2> ...");
int count = argc - 3;
share_t *shares = xmalloc(sizeof(*shares) * (size_t)count);
for (int i = 0; i < count; i++) shares[i] = read_share(argv[3 + i]);
validate_shares(shares, count);
int k = shares[0].k;
uint64_t len = shares[0].len;
uint8_t *secret = xmalloc((size_t)len);
for (uint64_t p = 0; p < len; p++) secret[p] = interpolate_at_zero(shares, k, p);
write_file(argv[2], secret, len);
printf("recovered %s (%" PRIu64 " bytes)\n", argv[2], len);
free(secret);
for (int i = 0; i < count; i++) free(shares[i].y);
free(shares);
}
static void selftest(void) {
if (gf_mul(0x57, 0x83) != 0xc1) die("GF multiply test failed");
for (int a = 1; a < 256; a++) {
if (gf_div((uint8_t)a, (uint8_t)a) != 1) die("GF inverse test failed");
}
uint8_t coef[3] = {0x42, 0x11, 0x99};
share_t s[3];
uint8_t y0 = poly_eval(coef, 3, 1);
uint8_t y1 = poly_eval(coef, 3, 2);
uint8_t y2 = poly_eval(coef, 3, 5);
s[0] = (share_t){3, 5, 1, 1, &y0};
s[1] = (share_t){3, 5, 2, 1, &y1};
s[2] = (share_t){3, 5, 5, 1, &y2};
if (interpolate_at_zero(s, 3, 0) != 0x42) die("Lagrange interpolation test failed");
puts("selftest: ok");
puts(" GF(256): 0x57 * 0x83 == 0xc1");
puts(" Lagrange: recovered f(0) from shares at x=1,2,5");
}
static uint64_t now_us(void) {
#ifdef _WIN32
LARGE_INTEGER freq, ctr;
QueryPerformanceFrequency(&freq);
QueryPerformanceCounter(&ctr);
return (uint64_t)((ctr.QuadPart * 1000000ULL) / freq.QuadPart);
#else
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
return (uint64_t)ts.tv_sec * 1000000ULL + (uint64_t)ts.tv_nsec / 1000ULL;
#endif
}
static void cmd_bench(int argc, char **argv) {
if (argc != 7) die("usage: bench <K> <N> <size-bytes> <rounds> <out.csv>");
int k = atoi(argv[2]);
int n = atoi(argv[3]);
uint64_t len = (uint64_t)strtoull(argv[4], NULL, 10);
int rounds = atoi(argv[5]);
if (k < 2 || n < k || n > MAX_SHARES || rounds < 1) die("bad bench parameters");
FILE *csv = fopen(argv[6], "wb");
if (!csv) {
perror(argv[6]);
exit(1);
}
fprintf(csv, "k,n,size,round,split_us,recover_us\n");
uint8_t *secret = xmalloc((size_t)len);
uint8_t *coef = xmalloc((size_t)k);
uint8_t *ys = xmalloc((size_t)n * (size_t)len);
uint8_t *recovered = xmalloc((size_t)len);
if (secure_random(secret, (size_t)len) != 0) die("random source failed");
for (int r = 0; r < rounds; r++) {
uint64_t t0 = now_us();
for (uint64_t p = 0; p < len; p++) {
coef[0] = secret[p];
if (secure_random(coef + 1, (size_t)(k - 1)) != 0) die("random source failed");
for (int x = 1; x <= n; x++) {
ys[(size_t)(x - 1) * (size_t)len + (size_t)p] = poly_eval(coef, k, (uint8_t)x);
}
}
uint64_t t1 = now_us();
share_t *shares = xmalloc(sizeof(*shares) * (size_t)k);
for (int i = 0; i < k; i++) {
shares[i].k = (uint8_t)k;
shares[i].n = (uint8_t)n;
shares[i].x = (uint8_t)(i + 1);
shares[i].len = len;
shares[i].y = ys + (size_t)i * (size_t)len;
}
uint64_t t2 = now_us();
for (uint64_t p = 0; p < len; p++) recovered[p] = interpolate_at_zero(shares, k, p);
uint64_t t3 = now_us();
if (memcmp(secret, recovered, (size_t)len) != 0) die("bench recovery mismatch");
free(shares);
fprintf(csv, "%d,%d,%" PRIu64 ",%d,%" PRIu64 ",%" PRIu64 "\n",
k, n, len, r, t1 - t0, t3 - t2);
}
fclose(csv);
free(recovered);
free(ys);
free(coef);
free(secret);
printf("wrote %s\n", argv[6]);
}
static void usage(void) {
puts("tiny-shamir - Shamir threshold sharing PoC");
puts("usage:");
puts(" tiny-shamir split <K> <N> <secret.bin> <share-prefix>");
puts(" tiny-shamir recover <out.bin> <share1> <share2> ...");
puts(" tiny-shamir selftest");
puts(" tiny-shamir bench <K> <N> <size-bytes> <rounds> <out.csv>");
}
int main(int argc, char **argv) {
if (argc < 2) {
usage();
return 2;
}
if (strcmp(argv[1], "split") == 0) {
cmd_split(argc, argv);
} else if (strcmp(argv[1], "recover") == 0) {
cmd_recover(argc, argv);
} else if (strcmp(argv[1], "selftest") == 0) {
selftest();
} else if (strcmp(argv[1], "bench") == 0) {
cmd_bench(argc, argv);
} else {
usage();
return 2;
}
return 0;
}
demo
compile it for Linux:
gcc -std=c11 -Wall -Wextra -O2 tiny_shamir.c -o tiny-shamir
Cross-compile for Windows:
x86_64-w64-mingw32-gcc -std=c11 -Wall -Wextra -O2 tiny_shamir.c -o tiny-shamir.exe -ladvapi32
The CLI is intentionally small:
./tiny-shamir split <K> <N> <secret.bin> <share-prefix>
./tiny-shamir recover <out.bin> <share1> <share2> ...
./tiny-shamir selftest
./tiny-shamir bench <K> <N> <size-bytes> <rounds> <out.csv>
Let’s create a tiny secret:
printf 'meow meow secret\nthreshold PoC\n' > secret.txt

Split it as 3-of-5:
./tiny-shamir split 3 5 secret.txt share
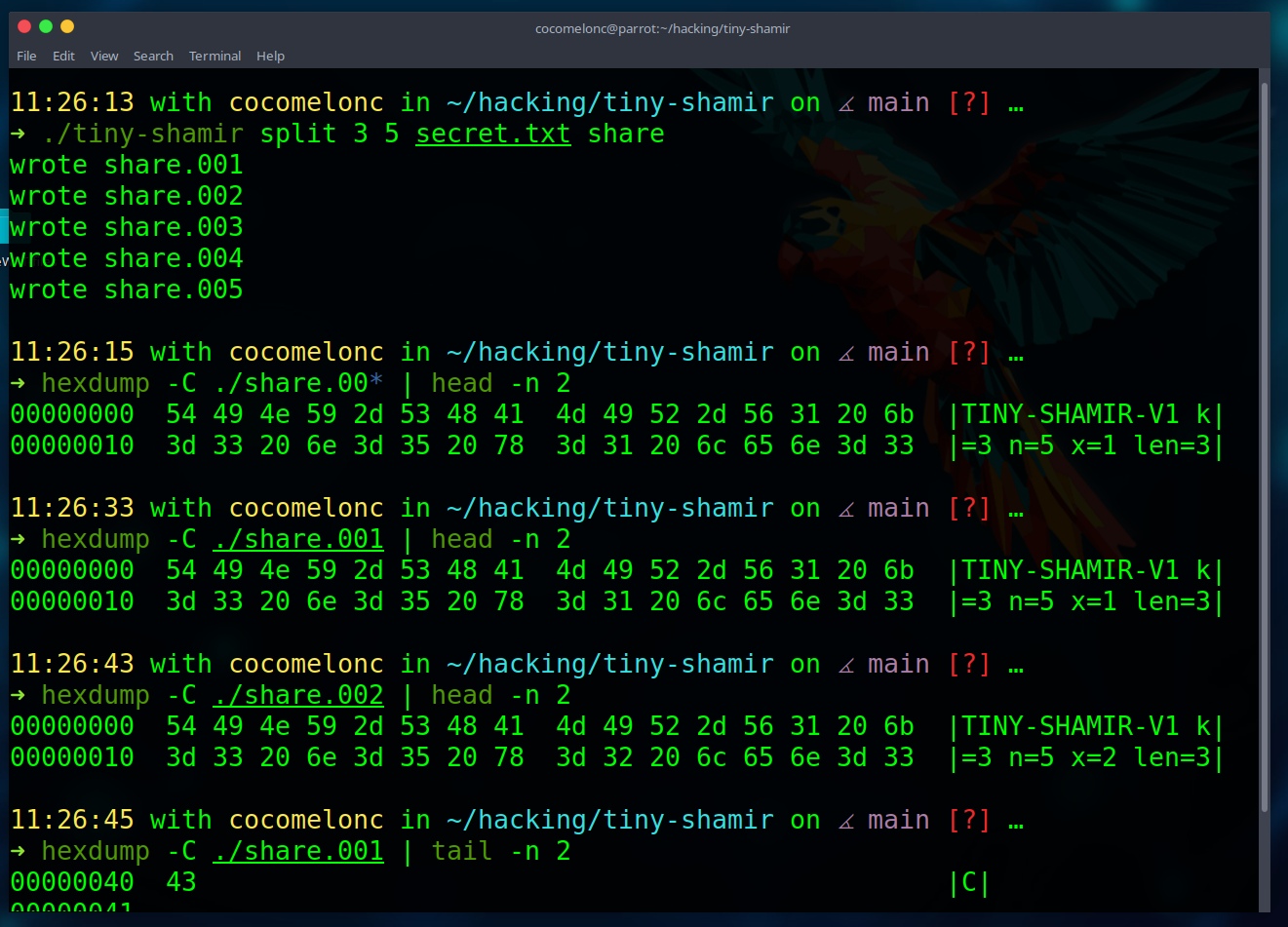
This creates five files:
share.001
share.002
share.003
share.004
share.005
Recover from shares 1, 2, and 3:
./tiny-shamir recover recovered-123.txt share.001 share.002 share.003
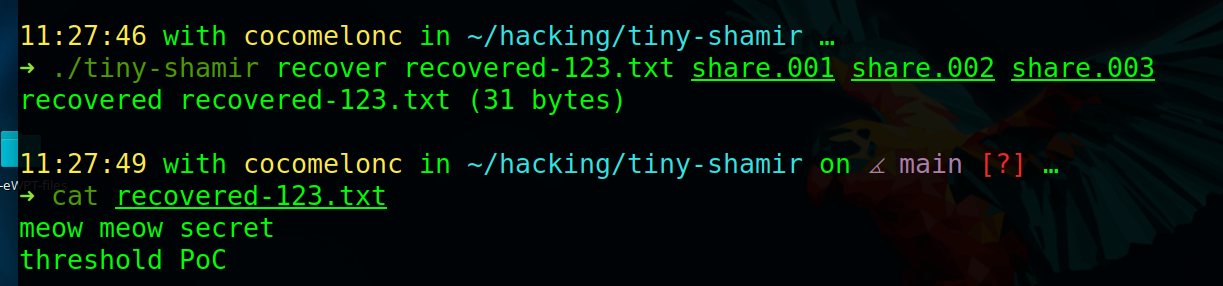
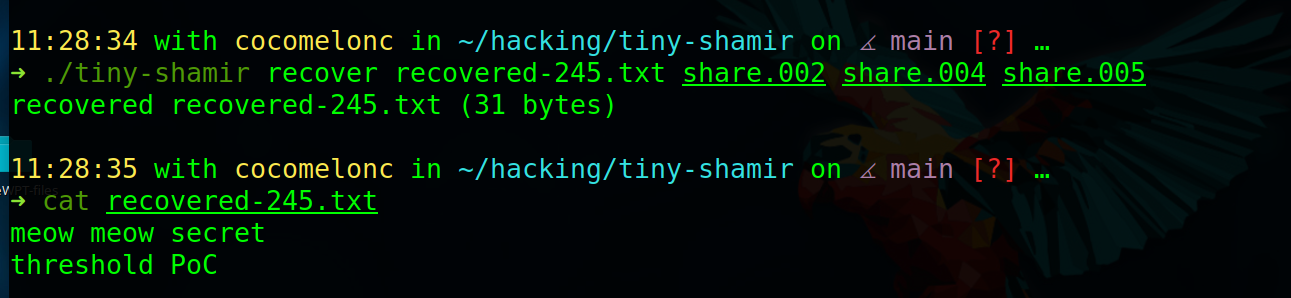
Recover from a different valid combination, for example 2, 4, and 5:
./tiny-shamir recover recovered-245.txt share.002 share.004 share.005
Check that the recovered files are identical:
sha256sum secret.txt recovered-123.txt recovered-245.txt

As you can see, both valid threshold combinations recover the same secret.
Now try to recover using only two shares:
./tiny-shamir recover bad.txt share.001 share.002

As you can see, the program rejects it with message:
error: not enough shares for threshold
This is exactly what we want.
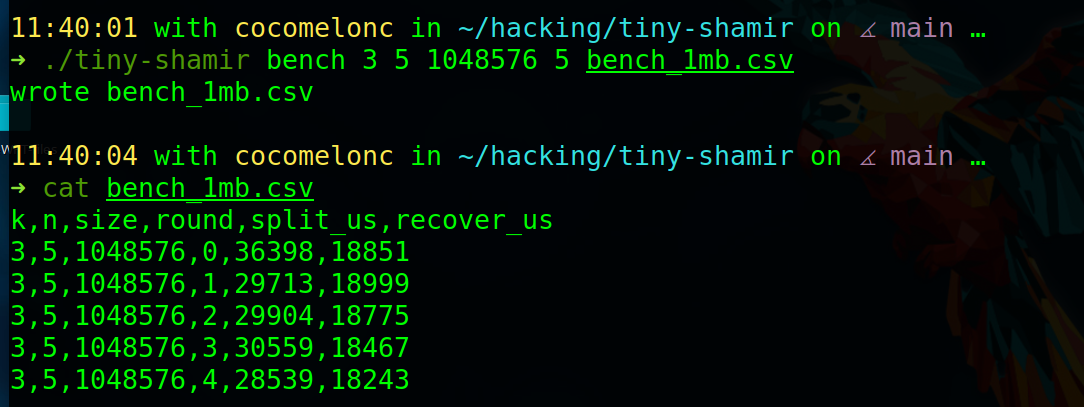
For a quick timing check, run the built-in benchmark:
./tiny-shamir bench 3 5 1048576 5 bench_1mb.csv
The two math graphs are generated by the small plotting script from the project:
python3 plot_math.py ./tiny-shamir ./tiny_shamir.c .
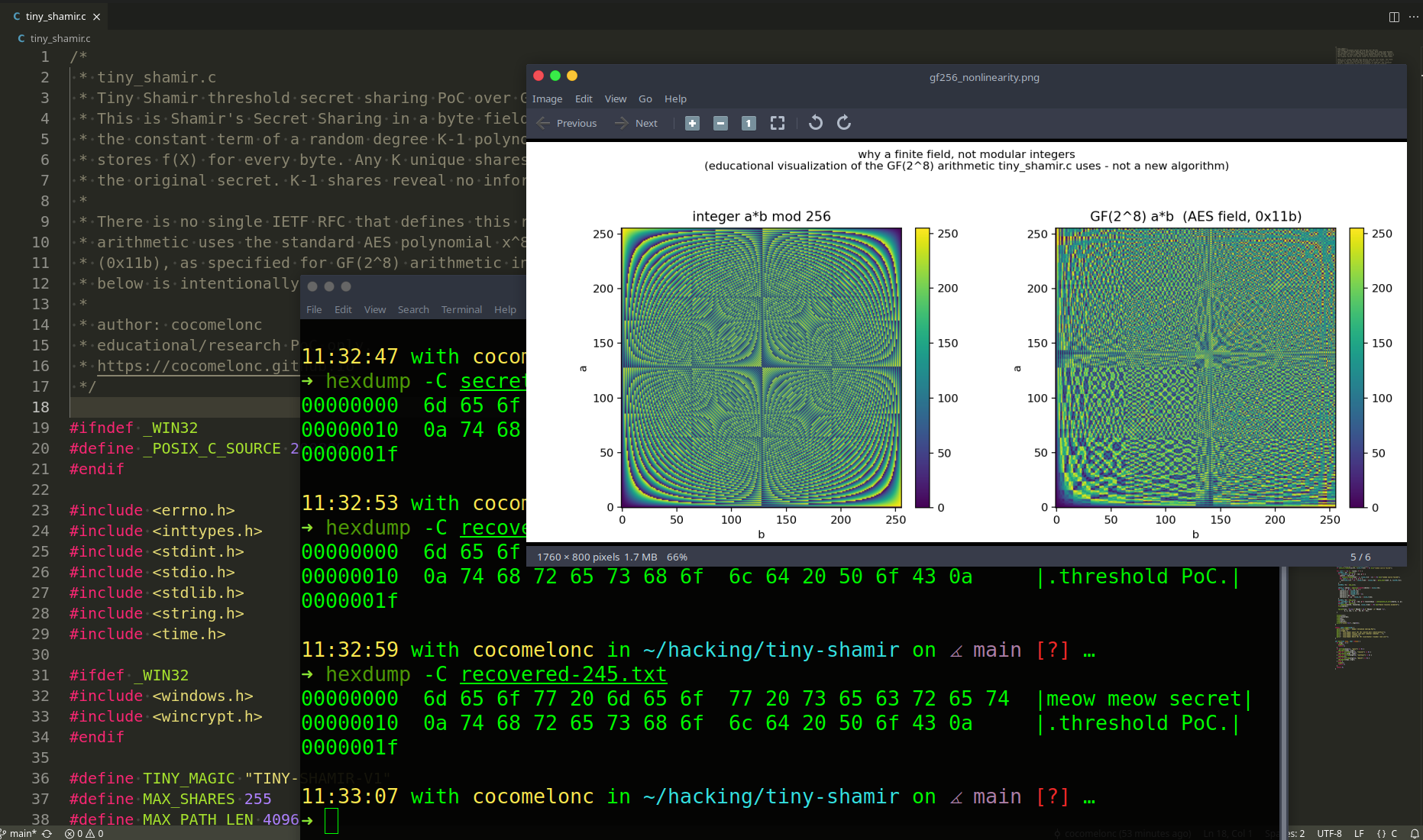
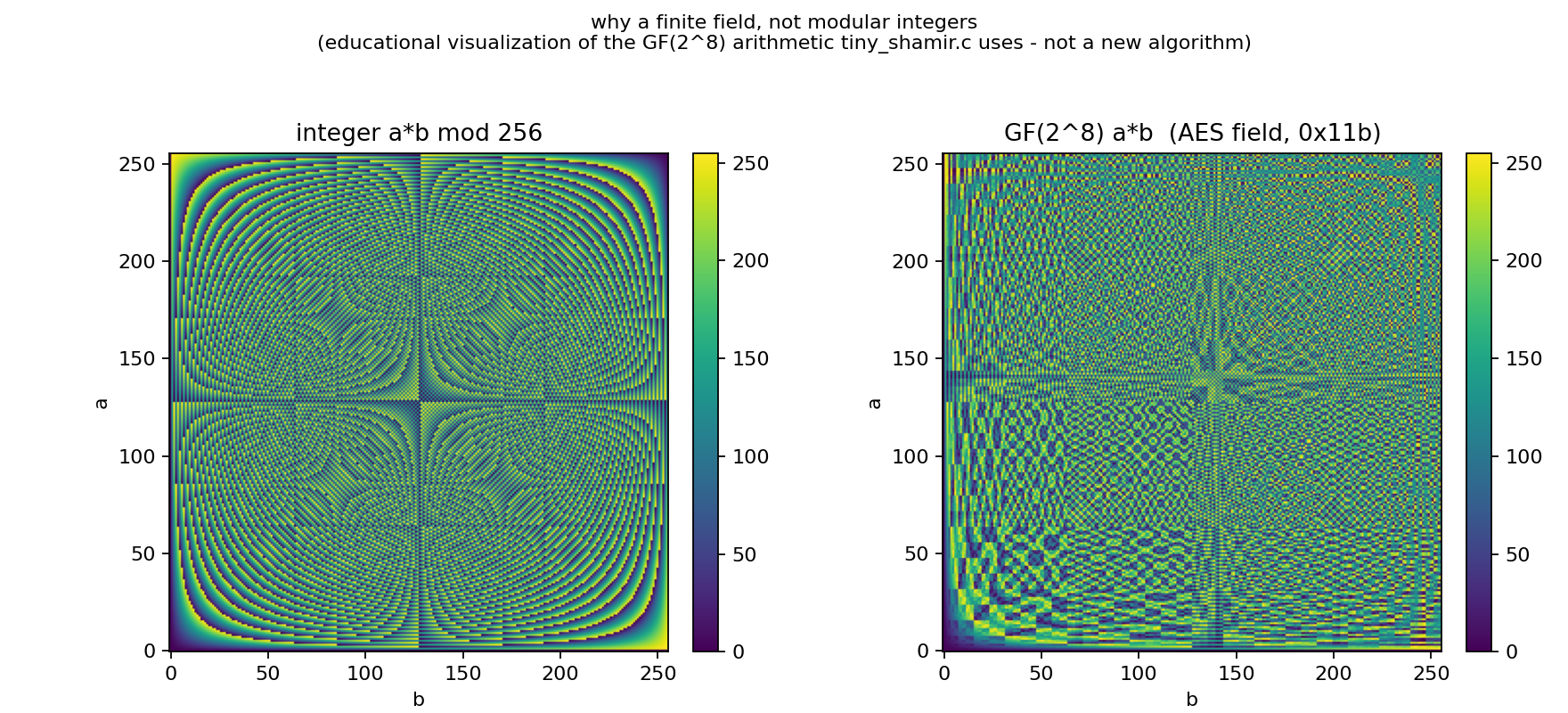
This command creates gf256_nonlinearity.png and entropy_secrecy.png in the current directory. The first graph compares multiplication in \(\mathrm{GF}(2^8)\) with plain integer multiplication modulo 256; it visually shows why we need real finite-field arithmetic instead of mod 256 arithmetic.
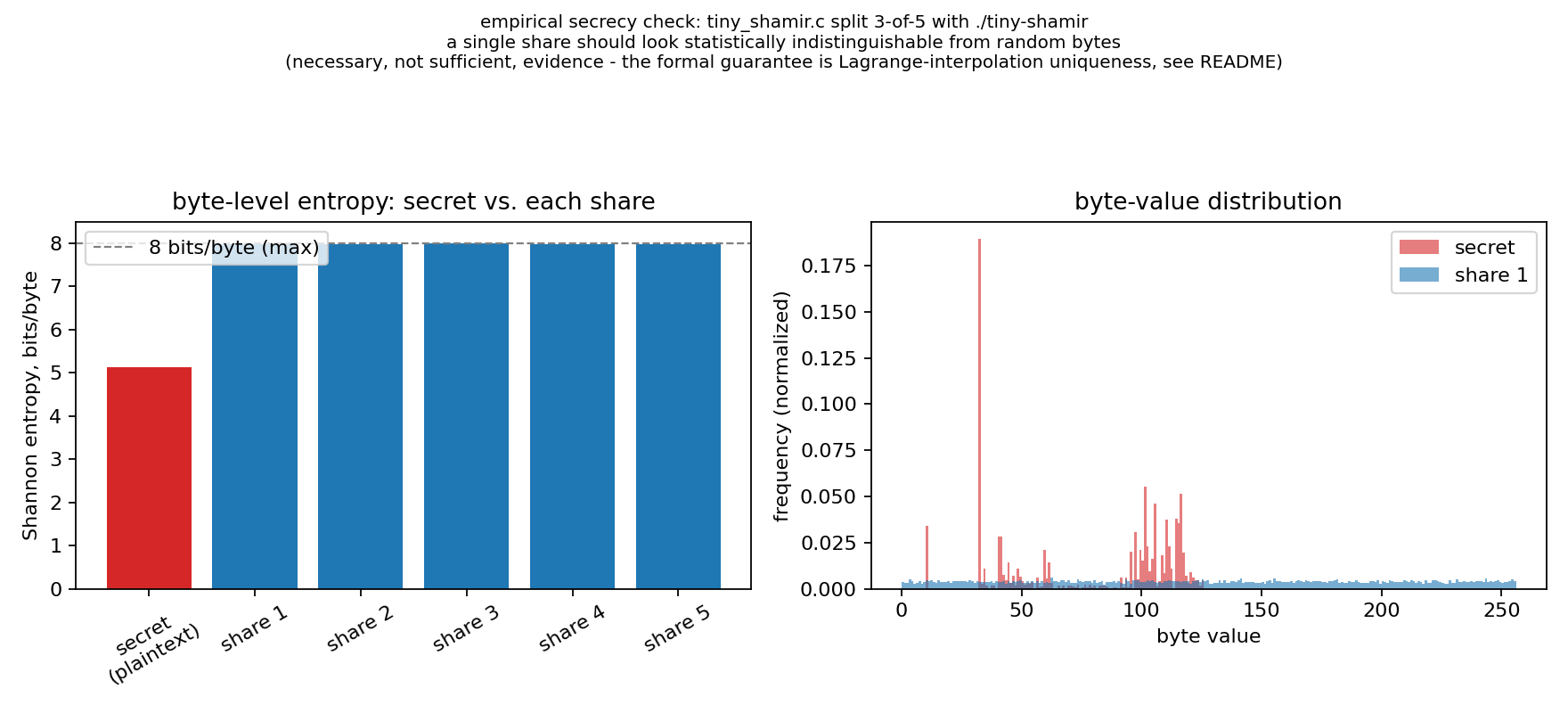
The second graph measures byte-value distributions and Shannon entropy for the original source file and the generated Shamir shares. The original file has structure, but the shares look close to random noise, which is exactly what we expect from random polynomial coefficients.
To run the dataset experiment and draw the graph, use the Python plotting helper:
python3 plot_dataset.py ./tiny-shamir ./dataset_1000 3 5 results_1000.csv results_1000.png
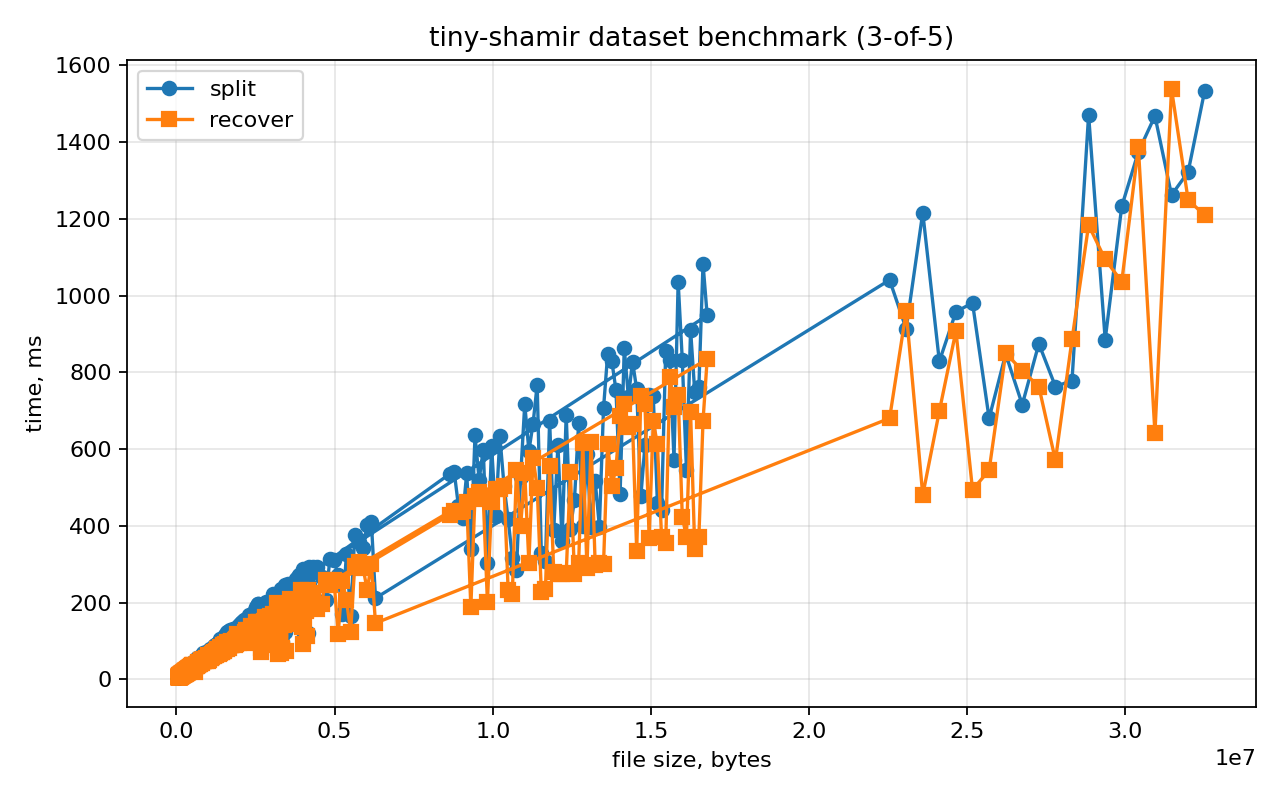
The CSV contains one row per file: file size, threshold parameters, split time, recover time, and the SHA-256 verification result. The graph plots file size on the X axis and time on the Y axis. The split line is usually higher because the program evaluates the polynomial for all N shares, while recover uses only K shares for interpolation.
self-test
The selftest command checks two things:
./tiny-shamir selftest
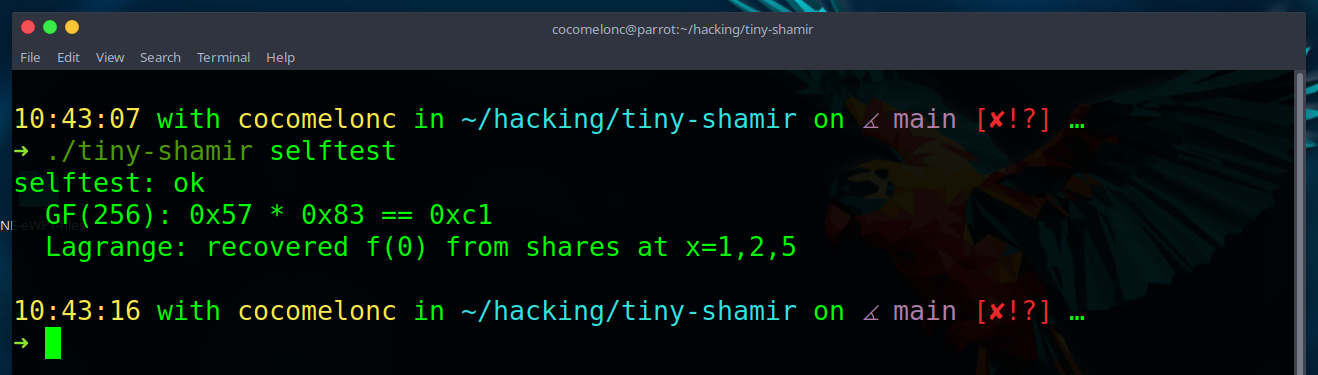
First, it checks a known AES field multiplication value:
\[0x57 \cdot 0x83 = 0xc1\]Second, it builds a known polynomial:
\[f(x) = 0x42 + 0x11x + 0x99x^2\]Then it evaluates the polynomial at:
x = 1, 2, 5
and confirms that Lagrange interpolation reconstructs:
\[f(0) = 0x42\]This is a small but useful sanity test: if field multiplication or interpolation is wrong, the entire scheme is broken.
conclusion
Shamir Secret Sharing is one of those cryptographic ideas that feels almost too simple when you first see it: hide a secret as \(f(0)\), give people points on the polynomial, and require enough points to reconstruct the polynomial. But the details matter: the math must happen over a field, random coefficients must be generated correctly, share coordinates must be distinct, and binary formats must be parsed carefully.
For malware and red team research, this gives us an interesting primitive: operational secrets do not have to live in one place. For blue team research, it is also a useful mental model: not every secret is stored as one obvious key blob. Sometimes a system only becomes dangerous when several fragments are combined.
This PoC is intentionally tiny, auditable, and boring in the right places. It is not a production secret-storage tool. It is a research implementation that makes the mathematics visible.
I hope this post is useful for malware researchers, cryptography enthusiasts, red teamers, and blue team specialists.
Adi Shamir - How to Share a Secret
FIPS 197 - Advanced Encryption Standard (AES)
Lagrange polynomial
Finite field arithmetic
Shamir’s Secret Sharing
source code in github
This is a practical case for educational purposes only.
Thanks for your time happy hacking and good bye!
PS. All drawings and screenshots are mine